- Published on
Google Agent白皮书解析:模型、工具与编排层全面指南
- Authors

- Name
- Shoukai Huang
目录
本文整理了Google Agent白皮书中的核心内容,并对部分概念进行了扩展解释,帮助读者更好地理解智能代理的工作原理和应用场景。原文链接:Google Agent白皮书
This combination of reasoning, logic, and access to external information that are all connected to a Generative AI model invokes the concept of an agent.
推理、逻辑和访问外部信息的结合都与生成式人工智能模型相连,这就引出了代理的概念。
什么是智能代理(Agent)?
a Generative AI agent can be defined as an application that attempts to achieve a goal by observing the world and acting upon it using the tools that it has at its disposal. Agents are autonomous and can act independently of human intervention, especially when provided with proper goals or objectives they are meant to achieve. Agents can also be proactive in their approach to reaching their goals. Even in the absence of explicit instruction sets from a human, an agent can reason about what it should do next to achieve its ultimate goal.
生成式 AI 代理可以定义为一种应用程序,它试图通过观察世界并使用其可用的工具对其采取行动来实现目标。代理是自主的,可以独立于人类干预而行动,尤其是在为它们提供了适当的目标或目的时。代理还可以主动实现目标。即使没有来自人类的明确指令集,代理也可以推理出下一步应该做什么才能实现其最终目标。
代理与模型
为了更清楚地理解代理和模型之间的区别,请考虑以下图表:
| 模型 | 代理 |
|---|---|
| 知识仅限于训练数据中可用的内容。 | 通过工具与外部系统的连接来扩展知识 |
| 根据用户查询进行单一推理/预测。除非明确为模型实现,否则不会管理会话历史或连续上下文。(即聊天记录) | 管理会话历史记录(即聊天历史记录),以便根据用户查询和在编排层做出的决策进行多轮推理/预测。在此上下文中,“轮次”定义为交互系统与代理之间的交互。(即 1 个传入事件/查询和 1 个代理响应) |
| 没有本机工具实现。 | 工具是在代理架构中原生实现的。 |
| 未实现本机逻辑层。用户可以将提示形成为简单问题,或使用推理框架(CoT、ReAct 等)形成复杂提示以指导模型进行预测。 | 使用推理框架(如 CoT、ReAct)或其他预构建代理框架(如 LangChain)的本机认知架构。 |
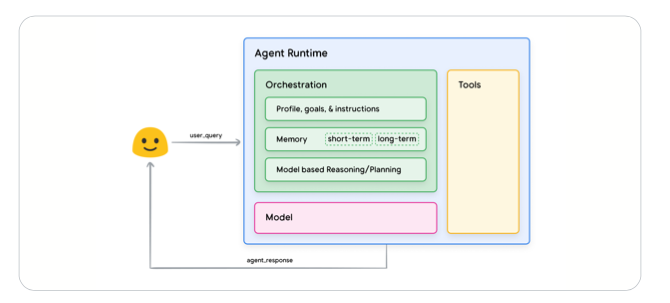
通用代理架构和组件
通用代理框架由:模型、工具、编排层组成;
- 模型:指将用作代理流程的集中决策者的语言模型 (LM)。代理使用的模型可以是一个或多个任意大小(小/大)的 LM,这些 LM 能够遵循基于指令的推理和逻辑框架,例如 ReAct、Chain-of-Thought 或 Tree-of-Thoughts。
- 工具:基础模型有无法与外界互动的限制,工具弥合这一差距,使代理能够与外部数据和服务进行交互,同时解锁超出底层模型本身能力的更广泛的操作。工具可以采用多种形式并具有不同的复杂程度,但通常与常见的 Web API 方法(如 GET、POST、PATCH 和 DELETE)保持一致。
- 编排层:编排层描述了一个循环过程,该过程控制代理如何获取信息、执行一些内部推理,并使用该推理来指导其下一步行动或决策。一般来说,这个循环将持续到代理达到其目标或停止点。
Agent 流行框架
流行的框架和推理技术,包括:ReAct、Chain-of-Thought 或 Tree-of-Thoughts。
ReAct框架
一种提示工程框架,它为语言模型提供了一种思维过程策略,使其能够推理并根据用户查询采取行动,无论是否带有上下文示例。ReAct 提示已被证明优于多个 SOTA 基线,并提高了 LLM 的人机互操作性和可信度。
ReAct, a prompt engineering framework that provides a thought process strategy for language models to Reason and take action on a user query, with or without in-context examples.
核心概念:是一种将推理和行动紧密结合的新方法,要求模型在推理过程中,能够根据推理结果自动生成并执行相应的动作,从而解决实际问题。
创新点:将推理和行动视为一个整体过程,通过交替进行推理和行动,使模型能够更好地适应复杂多变的环境。
应用实例:在智能家居场景中,ReAct可以使智能音箱在接收到用户指令后,首先通过推理判断指令的意图(如“打开空调”),然后自动生成并执行相应的动作(如向空调发送开启指令),从而完成用户请求。
Chain-of-Thought (CoT、思维链)
一种通过中间步骤实现推理能力的快速工程框架。CoT 有各种子技术,包括自洽性、主动快速和多模态 CoT,每种技术都有其优点和缺点,具体取决于具体应用。
a prompt engineering framework that enables reasoning capabilities through intermediate steps. There are various sub-techniques of CoT including self-consistency, active-prompt, and multimodal CoT that each have strengths and weaknesses depending on the specific application.
核心概念:通过模拟人类思维过程来提高模型推理能力,要求模型在回答问题时,不仅给出答案,还要展示出一步步的推理过程,形成一条逻辑链。
应用场景:特别适用于解决数学问题、逻辑推理等需要逐步推导的场景。比如解决“3+4×2等于多少”的数学题时,CoT会引导模型先计算乘法(4×2=8),再进行加法(3+8=11),从而得出正确答案。
实践建议:在实际应用中,可以通过在 Prompt 中加入“Let’s think step by step”等提示语,引导模型生成CoT。同时,利用微调和数据集优化,可以进一步提升模型的CoT能力。
Tree-of-thoughts (ToT、思维树)
一个提示工程框架,非常适合探索或战略性前瞻任务。它概括了思路链提示,并允许模型探索各种思路链,这些思路链是使用语言模型解决一般问题的中间步骤。
a prompt engineering framework that is well suited for exploration or strategic lookahead tasks. It generalizes over chain-of-thought prompting and allows the model to explore various thought chains that serve as intermediate steps for general problem solving with language models.
核心概念:是对CoT的进一步拓展,以树的形式组织问题解决策略,通过系统性地探索不同的思维路径,来增强模型的全面性和灵活性。
优势分析:能够同时考虑多个可能的推理路径,并通过前瞻和回溯来评估不同选择,有助于模型在面临复杂问题时,找到更优的解决方案。
实例说明:假设需要分析一个人的综合素质是否适合某项工作,ToT会首先分解问题为多个子问题(如专业技能、沟通能力、团队协作等),然后为每个子问题生成多个可能的推理路径,并通过综合评估来选择最合适的答案。
三者区别
ReAct 与 CoT 和 ToT 的本质区别在于,ReAct不止在推理,还在利用外部工具实现目标。CoT 和 ToT 主要作用在大模型本身的内在推理过程上,而 ReAct 则是统筹整个系统,从推理过程结合外部工具共同实现最终目标。
Tools: Our keys to the outside world(通向外部世界的钥匙)
Google 模型能够与三种主要工具类型交互:扩展(Extension)、函数(Function)和数据存储。
- 扩展:理解扩展的最简单方法是将其视为以标准化方式弥合 API 和代理之间的差距,让代理可以无缝执行 API,而不管其底层实现如何。
- 函数:模型可以采用一组已知函数,并根据其规范决定何时使用每个函数以及函数需要哪些参数。
- 数据存储:允许开发人员以原始格式向代理提供额外数据,从而无需进行耗时的数据转换、模型重新训练或微调。数据存储将传入的文档转换为一组向量数据库嵌入代理可以使用它来提取所需的信息,以补充其下一步操作或对用户的响应。
扩展和函数区别:
模型输出函数及其参数,但不会进行实时 API 调用。
函数在客户端,而扩展则在代理端。
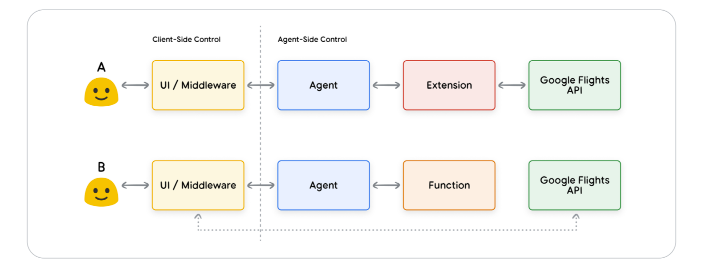
开发人员选择使用函数而不是扩展的原因:
- API 调用需要在应用程序堆栈的另一层进行,在直接代理架构流程之外(例如中间件系统、前端框架等)
- 安全或身份验证限制阻止代理直接调用 API(例如,API 未暴露给互联网,或代理基础设施无法访问)
- 时间或操作顺序限制阻止代理实时进行 API 调用。(即批量操作、人机交互审查等)
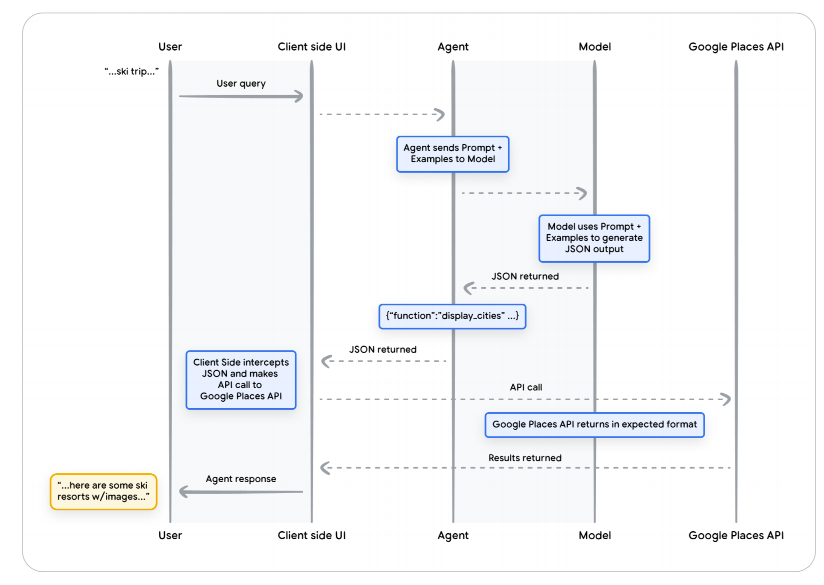
Function:函数调用生命周期的序列图
三种工具类型对比
| 特性 | 扩展(Extensions) | 函数调用(Function Calling) | 数据存储(Data Stores) |
|---|---|---|---|
| 执行位置 | 代理端 | 客户端 | 代理端 |
| 适用场景 |
|
|
|
通过有针对性的学习增强模型能力
为了帮助模型获取此类特定知识,有以下几种方法:
- 情境学习:该方法提供了一个通用模型,该模型在推理时具有提示、工具和少量样本,使其能够“动态”学习如何以及何时使用这些工具来完成特定任务。ReAct 框架是这种方法在自然语言中的一个例子。
- 基于检索的上下文学习:该技术通过从外部存储器检索最相关的信息、工具和相关示例,动态地将这些信息、工具和相关示例填充到模型提示中。Vertex AI 扩展中的“示例存储”或前面提到的。基于 RAG 架构的数据存储就是一个例子。
- 基于微调的学习:该方法涉及在推理之前使用更大的特定示例数据集来训练模型。这有助于模型在收到任何用户查询之前了解何时以及如何应用某些工具。
重新回顾一下烹饪类比。
- 假设一位厨师从一位顾客那里收到了一份特定的食谱(提示)、一些关键配料(相关工具)和一些示例菜品(少量示例)。基于这些有限的信息和厨师对烹饪的一般了解,他们需要弄清楚如何“即时”准备最符合食谱和顾客喜好的菜肴。这是情境学习。
- 现在让我们想象一下,我们的厨师在厨房里,厨房里有一个储备充足的食品储藏室(外部数据存储),里面装满了各种配料和食谱(示例和工具)。厨师现在可以从食品储藏室动态选择配料和食谱,更好地满足顾客的食谱和偏好。这样,厨师就可以利用两者创造出更明智、更精致的菜肴现有知识和新知识。 这是基于检索的情境学习。
- 最后,让我们想象一下,我们让厨师回到学校学习一种或一组新菜系(在更大的特定示例数据集上进行预训练)。这让厨师能够以更深入的理解来处理未来未见过的客户食谱。如果我们希望厨师在特定菜系(知识领域)上表现出色,这种方法是完美的。这是基于微调的学习。
代理快速开始使用 LangChain
LangChain 和 LangGraph 库构建一个快速原型,代码略
具有 Vertex AI 代理的生产应用程序
Vertex AI 平台构建代理介绍,过程略
本白皮书的关键要点总结
- 代理通过利用工具访问实时信息、建议现实世界的操作以及自主计划和执行复杂任务来扩展语言模型的功能。代理可以利用一个或多个语言模型来决定何时以及如何转换状态,并使用外部工具来完成模型难以或无法自行完成的任意数量的复杂任务。
- 代理操作的核心是编排层,这是一种认知架构,用于构建推理、规划、决策并指导其行动。各种推理技术(如 ReAct、思维链和思维树)为编排层提供了一个框架,用于接收信息、执行内部推理并生成明智的决策或响应。
- 扩展、函数和数据存储等工具是代理与外部世界沟通的钥匙,使它们能够与外部系统交互并访问训练数据以外的知识。扩展在代理和外部API之间架起了一座桥梁,使API调用得以执行并检索实时信息。函数通过分工为开发人员提供了更细致的控制,使代理能够生成可在客户端执行的函数参数。数据存储为代理提供了对结构化或非结构化数据的访问,从而实现了数据驱动的应用程序。