- Published on
Cognee 实战:构建 AI Agent 的可计算记忆层
- Authors

- Name
- Shoukai Huang

Cognee 实战:构建 AI Agent 的可计算记忆层(Photo by Kelly Sikkema on Unsplash )
在 AI Agent 与 RAG 系统逐步走向工程化的当下,单纯依赖向量检索,已经越来越难支撑“可追踪、可关联、可复用”的长期记忆需求。cognee 值得关注,正因为它试图把文档切片、向量表示、来源追踪与知识图谱整合成一层可计算记忆,让数据不仅能被检索,还能被结构化理解和调用。
本文将结合代码实践,从三个层面展开:先解释 cognee 是什么,以及它与传统向量检索方案的差异;再说明它的存储与处理架构;最后通过一个最小可运行示例,验证它在本地工程中的接入方式与实际效果。示例的目标也很明确:使用阿里云百炼的 OpenAI 兼容接口作为大模型与 embedding 来源,把一份 PDF 和多份 markdown 一起写入 cognee,执行 cognify 构建知识图谱和检索上下文,再通过 LangChain 的最小 agent 对入库后的数据发起查询。
1. Cognee 是什么
cognee 可以理解为一个把原始数据转换成“可搜索、可关联、可被智能体调用的记忆层”的开源工具与平台。它不只是做向量检索,而是把文档、切片、来源信息、embedding、实体关系这些信息一起组织起来,让数据既能按语义搜索,也能按结构和关系连接。
你可以把它看作位于模型和原始资料之间的一层“可计算记忆”:
- 原始文档进入系统后,不再只是静态文件
- 文档会被切分、向量化,并建立来源追踪
- 关键实体与关系会被组织成图结构
- 智能体或应用查询时,可以利用语义相似度和图关系联合取回结果
官方介绍可以概括为下面这段话:
Cognee is an open source tool and platform that transforms your raw data into intelligent, searchable memory. It combines vector search with graph databases to make your data both searchable by meaning and connected by relationships.
对于工程实践者来说,cognee 的价值主要体现在三个层面:
- 它把“文档入库”从简单的文本嵌入,扩展成了包含 provenance、chunk、embedding、graph 的完整处理链路。
- 它让“搜索”不再只是 top-k 语义相似文本,而是有机会结合知识图谱中的实体和关系。
- 它天然适合作为 agent 的外部知识工具,被
LangChain之类的框架直接调用。
这也是本文选择它做实践验证的原因。
2. Cognee 架构说明
cognee 的一个关键设计点,是它并不假设“单一数据库”可以同时处理记忆系统的全部需求。它把存储层拆成了三个互补角色,并通过统一运行时把它们组织起来。
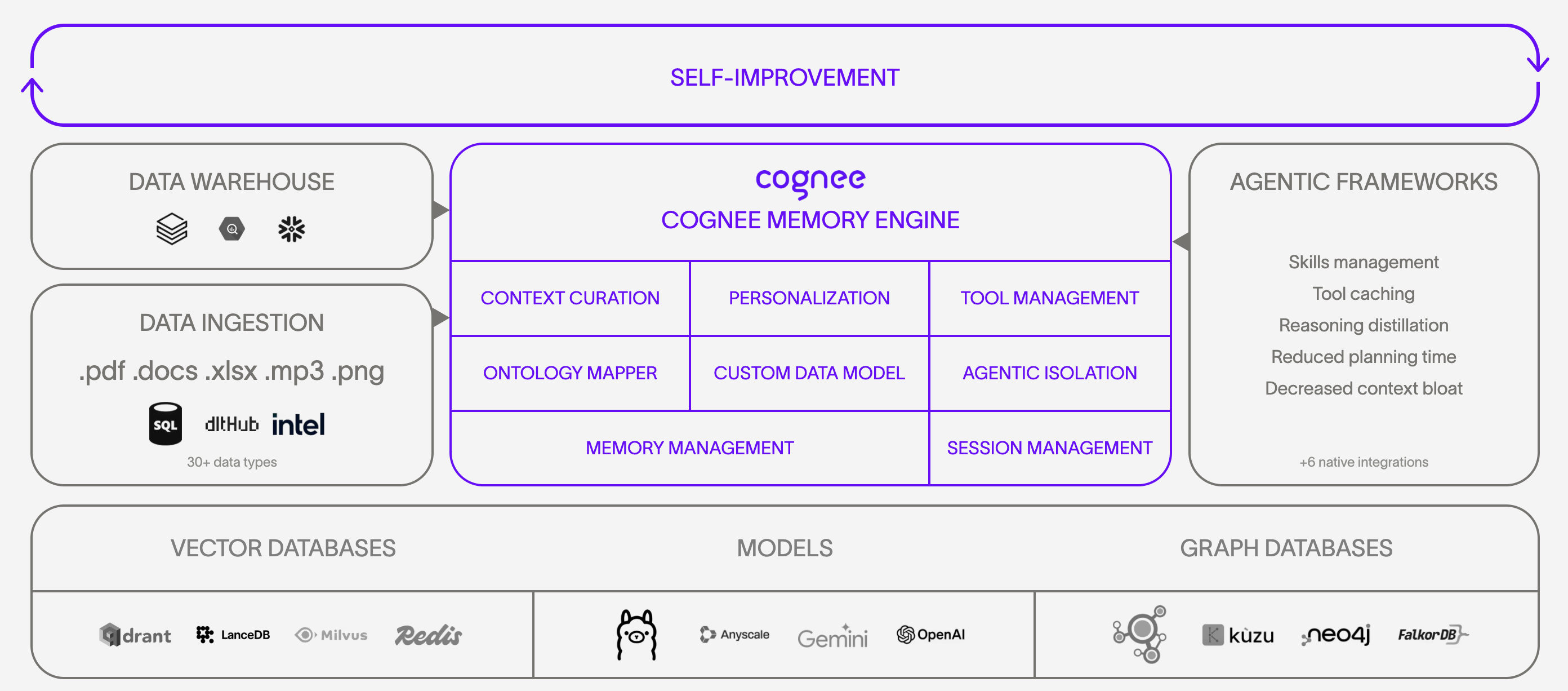
Cognee 架构图
上图表达的核心思想可以概括为下面三层:
Relational store负责记录文档、文档切片、元数据和 provenance,也就是“这段内容来自哪里、如何和原文关联”。Vector store负责存储 embedding,用于语义相似检索。哪怕用户问题和原文措辞不同,只要语义接近,系统也能召回相关内容。Graph store负责实体与关系的表示,构建知识图谱。这样系统不只是在“找相似文本”,还能理解“谁和谁有关”“概念之间如何连接”。
这三者组合起来,才更接近“可用的记忆系统”:
- 关系型存储保证来源可追踪
- 向量存储保证语义召回能力
- 图存储保证结构化理解和关系导航
cognee 默认提供了适合本地实验的轻量方案,同时也允许你替换成更适合生产环境的后端。这种设计对 PoC 很友好,因为你可以先用本地模式快速完成验证,再逐步替换底层存储。
从本文的示例来看,这种架构特别适合验证一个问题:当一份论文 PDF 和几份人工整理的 markdown 同时进入系统后,查询结果能否既命中原文,又带上结构化备注中的重点结论。如果能做到这一点,就说明 cognee 不只是把文件“塞进去”,而是真正形成了可检索、可关联的上下文层。
3. 代码验证
3.1 本文验证思路
本文使用的是当前仓库中的最小中文示例工程,验证目标并不是“做一个复杂的生产级 RAG 系统”,而是验证 cognee 的几个核心能力:
- 能否把多种格式文档统一写入同一数据集。
- 查询时能否同时命中 PDF 原文与人工整理的 markdown。
LangChainagent 能否把cognee当成外部知识工具来调用。
为了让这个验证尽量清晰,项目特意保持最小闭环:
- 入库脚本只负责加载配置、检查文件、执行
add + cognify - 查询脚本只负责构造一个最小 agent 并调用
search_cognee
本文不验证以下内容:
- 多数据集隔离
- Web 服务接口
- 长流程 agent 编排
- 自动化真实联网集成测试
成功标准也很直接:
ingest_demo.py能顺利完成add + cognify- 查询时不会出现空知识图谱
- 回答内容能明显同时参考 PDF 与 markdown
agent_demo.py能完成一次最小 agent 闭环
3.2 环境准备与配置过程
先复制环境变量模板:
cp .env.example .env
当前项目中的 .env.example 如下:
OPENAI_API_KEY=your_dashscope_api_key
OPENAI_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
OPENAI_MODEL=qwen3.5-plus
OPENAI_EMBEDDING_MODEL=text-embedding-v4
OPENAI_EMBEDDING_ENDPOINT=https://dashscope.aliyuncs.com/api/v1/services/embeddings/text-embedding/text-embedding
OPENAI_EMBEDDING_DIMENSIONS=1024
OPENAI_EMBEDDING_MAX_TOKENS=8192
# Cognee stores local files here for the demo.
COGNEE_DATA_DIR=.cognee
这几个字段的职责分别是:
OPENAI_API_KEY阿里云百炼的 API Key。OPENAI_BASE_URL百炼的 OpenAI 兼容接口基地址。OPENAI_MODEL聊天模型名,例如qwen3.5-plus。OPENAI_EMBEDDING_MODELembedding 模型名,例如text-embedding-v4。OPENAI_EMBEDDING_ENDPOINT百炼原生 embedding endpoint,本项目用它兼容cognee的 embedding 调用。OPENAI_EMBEDDING_DIMENSIONSembedding 维度。OPENAI_EMBEDDING_MAX_TOKENSembedding 最大 token 数,用于运行时 patch。COGNEE_DATA_DIR本地数据目录,默认落在项目内的.cognee。
安装依赖:
env UV_CACHE_DIR=/tmp/uv-cache uv sync --python 3.12
这里的关键点不只是“安装成功”,还包括两项兼容性处理:
- LLM 仍然走 OpenAI 兼容协议。
- embedding provider 被显式设置成
openai_compatible,并对百炼原生 embedding endpoint 做了运行时补丁。
这是本文实践最核心的工程处理之一,因为很多问题都集中在 embedding 这一层。
3.3 数据准备与项目结构
本示例的数据设计非常克制,核心目标不是“语料规模”,而是“验证路径清晰”。
项目中真正参与验证的主要数据包括:
examples/data/attention_is_all_you_need.pdfTransformer 论文原文。examples/data/sample_notes.md背景、目标和成功标准。examples/data/experiment_findings.md实验观察记录,强调需要命中的重点结论。examples/data/qa_reference.md术语表、推荐问法、排错提示。
此外,还有一份单独的推荐提问清单:
examples/query_examples.md
核心代码文件包括:
examples/ingest_demo.pyexamples/agent_demo.pysrc/cognee_samples/demo_config.pysrc/cognee_samples/demo_data.pysrc/cognee_samples/cognee_runtime.pysrc/cognee_samples/agent_cli.py
这个项目结构说明了一个很清晰的设计取向:把“可运行示例”和“运行时封装”分开。examples/ 下是用户直接执行的入口,src/cognee_samples/ 下则集中放配置读取、路径管理、运行时兼容层和搜索封装。
3.4 执行入库:ingest_demo.py
入库命令如下:
env UV_CACHE_DIR=/tmp/uv-cache uv run --python 3.12 python examples/ingest_demo.py
这个脚本的执行流程分成 5 步:
- 加载
.env与运行配置 - 打印协议格式与连通性探测
- 检查示例数据文件
- 写入
cognee并执行cognify - 输出完成提示
脚本入口如下:
from __future__ import annotations
import asyncio
import sys
from cognee_samples.cognee_runtime import (
build_protocol_debug_report,
run_endpoint_diagnostics,
build_runtime_help_message,
ensure_demo_inputs_exist,
ingest_demo_dataset,
load_demo_config,
)
async def main() -> None:
print("步骤 1/5:加载 .env 与运行配置")
config = load_demo_config()
print(f"已读取模型配置:{config.openai_model} / {config.openai_embedding_model}")
print("步骤 2/5:打印协议格式与连通性探测")
print(build_protocol_debug_report(config))
print(await run_endpoint_diagnostics(config))
print("步骤 3/5:检查示例数据文件")
document_paths = ensure_demo_inputs_exist()
for path in document_paths:
print(f"- {path}")
print("步骤 4/5:写入 cognee 并执行 cognify")
dataset_name = await ingest_demo_dataset()
print("步骤 5/5:入库完成")
print(f"已完成数据集构建:{dataset_name}")
print("下一步请运行:uv run python examples/agent_demo.py")
if __name__ == "__main__":
try:
asyncio.run(main())
except Exception as error:
print(build_runtime_help_message(error), file=sys.stderr)
sys.exit(1)
这个脚本有两个很实用的设计点:
- 在真正调用
cognee前,先打印协议调试信息和连通性探测结果。 - 把所有常见错误统一转换成中文提示,降低定位成本。
这意味着它不仅是“入库脚本”,还是一个带自诊断能力的示例入口。
3.5 执行查询:agent_demo.py
当入库完成后,执行查询脚本:
env UV_CACHE_DIR=/tmp/uv-cache uv run --python 3.12 python examples/agent_demo.py
如果要传入自定义问题,可以直接在命令行中追加参数:
env UV_CACHE_DIR=/tmp/uv-cache uv run --python 3.12 python examples/agent_demo.py "Transformer 为什么更适合并行计算?"
agent_demo.py 做的事情其实很少,但足以形成最小 agent 闭环:
- 读取配置
- 解析命令行问题
- 用
ChatOpenAI初始化模型 - 注册
search_cognee工具 - 调用
create_agent - 把问题交给 agent,由 agent 再调用
cognee
这类最小示例非常适合做能力验证,因为你能清楚区分“模型本身的回答能力”和“是否真正调用了外部知识工具”。
3.6 关键实现拆解
这个项目最值得看的实现并不在脚本入口,而是在 src/cognee_samples/cognee_runtime.py 中。下面按几个关键点拆解。
1. 配置读取与约束
demo_config.py 中定义了 DemoConfig,并通过 build_demo_config() 从环境变量读取最小配置集合。它做了三件很重要的事:
- 对关键环境变量做缺失校验
- 对整数配置做类型转换
- 对
OPENAI_BASE_URL做归一化,避免用户误填成完整 endpoint
这能提前拦截很多本应在运行前暴露的问题。
2. 统一封装 cognee 初始化
configure_cognee() 负责所有与 cognee 初始化相关的动作,包括:
- 固定
.cognee/data和.cognee/system目录 - 设置 LLM provider、模型名、endpoint、额外参数
- 设置 embedding provider 为
openai_compatible - 设置 embedding 的模型、维度和 endpoint
其中最关键的一句是:
cognee.config.set_embedding_provider("openai_compatible")
如果把这里改回普通 openai,就很可能重新遇到百炼 embedding 模型与 tokenizer 映射不兼容的问题。
3. 为百炼 embedding 做运行时补丁
_patch_openai_compatible_embedding_engine() 是整个项目最有工程价值的部分。它通过 monkey patch 改写了 OpenAICompatibleEmbeddingEngine 的初始化和 embed_text() 方法,以支持百炼原生 embedding endpoint。
补丁主要解决了三类问题:
- 原生 endpoint 不是标准 OpenAI
/v1/embeddings形式 - 模型最大 token 需要从环境中显式传递
- 单条文本过长时,需要自动拆分并合并 embedding 结果
这也是为什么当前示例不仅能“跑起来”,而且对 DashScope 的特殊接口做了兼容处理。
4. 先做 endpoint 探测,再决定是否跳过内置探测
run_endpoint_diagnostics() 会先对 LLM 和 embedding endpoint 做主动探测。如果两者都成功,它会自动设置:
COGNEE_SKIP_CONNECTION_TEST=true
这个设计很实用,因为它把“先验证连通性,再跳过内部重复探测”自动化了。对于排错来说,这比盲目重跑更高效。
5. 把查询工具适配为 agent 可消费文本
在 agent_demo.py 中,search_cognee() 并不直接把原始返回对象丢给 agent,而是统一转成字符串:
for item in results:
rendered.append(str(getattr(item, "search_result", item)))
这样做的目的很简单:兼容 cognee 返回结果在不同情况下可能呈现的不同对象结构,避免 agent 端因为类型不一致而出错。
6. 轻量测试保护关键约定
仓库里的测试没有做真实联网,而是聚焦在最重要的工程约定上:
- 环境变量是否完整读取
- 数据路径是否符合约定
- embedding provider 是否保持为
openai_compatible - 命令行问题解析是否符合预期
- 常见报错是否能转成可读提示
这种测试策略对示例工程尤其合适,因为它关注的是“关键契约是否被破坏”。
3.7 完整源码
这一节完整贴出当前仓库中的文本源码、配置文件和示例 markdown,保持原样,不做改写。唯一无法以内联源码形式展示的是二进制 PDF 文件 examples/data/attention_is_all_you_need.pdf,这里仅保留其路径说明。
PDF 资源
examples/data/attention_is_all_you_need.pdf
.env.example
OPENAI_API_KEY=your_dashscope_api_key
OPENAI_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
OPENAI_MODEL=qwen3.5-plus
OPENAI_EMBEDDING_MODEL=text-embedding-v4
OPENAI_EMBEDDING_ENDPOINT=https://dashscope.aliyuncs.com/api/v1/services/embeddings/text-embedding/text-embedding
OPENAI_EMBEDDING_DIMENSIONS=1024
OPENAI_EMBEDDING_MAX_TOKENS=8192
# Cognee stores local files here for the demo.
COGNEE_DATA_DIR=.cognee
pyproject.toml
[project]
name = "cognee-samples"
version = "0.1.0"
description = "Minimal cognee + LangChain demos with OpenAI-compatible models"
readme = "README.md"
requires-python = ">=3.12,<3.13"
dependencies = [
"cognee>=0.5.7",
"langchain>=1.2.15",
"langchain-openai>=1.1.12",
"pypdf>=6.9.2",
"python-dotenv>=1.2.2",
]
[build-system]
requires = ["hatchling"]
build-backend = "hatchling.build"
[tool.hatch.build.targets.wheel]
packages = ["src/cognee_samples"]
[dependency-groups]
dev = [
"pytest>=9.0.2",
]
main.py
def main():
print("先运行 `uv run python examples/ingest_demo.py`,再运行 `uv run python examples/agent_demo.py`。")
if __name__ == "__main__":
main()
examples/ingest_demo.py
from __future__ import annotations
import asyncio
import sys
from cognee_samples.cognee_runtime import (
build_protocol_debug_report,
run_endpoint_diagnostics,
build_runtime_help_message,
ensure_demo_inputs_exist,
ingest_demo_dataset,
load_demo_config,
)
async def main() -> None:
print("步骤 1/5:加载 .env 与运行配置")
config = load_demo_config()
print(f"已读取模型配置:{config.openai_model} / {config.openai_embedding_model}")
print("步骤 2/5:打印协议格式与连通性探测")
print(build_protocol_debug_report(config))
print(await run_endpoint_diagnostics(config))
print("步骤 3/5:检查示例数据文件")
document_paths = ensure_demo_inputs_exist()
for path in document_paths:
print(f"- {path}")
print("步骤 4/5:写入 cognee 并执行 cognify")
dataset_name = await ingest_demo_dataset()
print("步骤 5/5:入库完成")
print(f"已完成数据集构建:{dataset_name}")
print("下一步请运行:uv run python examples/agent_demo.py")
if __name__ == "__main__":
try:
asyncio.run(main())
except Exception as error:
print(build_runtime_help_message(error), file=sys.stderr)
sys.exit(1)
examples/agent_demo.py
from __future__ import annotations
import asyncio
import sys
from langchain.agents import create_agent
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from cognee_samples.agent_cli import resolve_question
from cognee_samples.cognee_runtime import (
build_runtime_help_message,
load_demo_config,
search_demo_dataset,
)
@tool
def search_cognee(question: str) -> str:
"""查询已经完成入库的数据集,并返回适合 agent 消费的文本。"""
results = asyncio.run(search_demo_dataset(question))
if not results:
return "No cognee results were returned. Run examples/ingest_demo.py first."
rendered = []
for item in results:
# cognee 的返回对象可能是 SearchResult,也可能已经是可打印结构。
rendered.append(str(getattr(item, "search_result", item)))
return "\n\n".join(rendered)
def main() -> None:
config = load_demo_config()
question = resolve_question(sys.argv)
# LangChain 这里直接使用 OpenAI 兼容接口,因此可以复用百炼配置。
model = ChatOpenAI(
api_key=config.openai_api_key,
base_url=config.openai_base_url,
model=config.openai_model,
temperature=0,
extra_body={"enable_thinking": False},
)
agent = create_agent(model=model, tools=[search_cognee])
response = agent.invoke(
{
"messages": [
{
"role": "user",
"content": (
"Use the search_cognee tool to answer the question. "
f"Question: {question}"
),
}
]
}
)
final_message = response["messages"][-1]
print("用户问题:")
print(question)
print("\nAgent 回答:")
print(final_message.content)
if __name__ == "__main__":
try:
main()
except Exception as error:
print(build_runtime_help_message(error), file=sys.stderr)
sys.exit(1)
examples/query_examples.md
# 推荐提问清单
以下问题可以直接用于验证这套示例是否已经正确把 PDF 和 markdown 一起纳入检索范围。
1. Transformer 论文里 self-attention 的核心优势是什么?
2. 为什么 Transformer 比循环网络更适合并行计算?
3. 这套示例数据最关注哪三个主题?
4. markdown 里的实验观察和论文原文有哪些互相印证的点?
5. 这次第一轮验证成功的标准是什么?
6. 结合论文和实验记录,总结一下 long-range dependencies 为什么重要?
7. 论文中提到的 attention 机制与我们在 markdown 中记录的验证目标有什么关系?
8. 如果我想判断 `cognee` 是否真的联合使用了多个文档,应该观察什么?
9. 这套示例里的结构化备注为 PDF 检索带来了什么帮助?
10. 结合所有文档,用一段话解释为什么这个项目要同时保留 PDF 和人工整理的 markdown。
examples/data/sample_notes.md
# Cognee 示例背景说明
这份 markdown 与 Transformer 论文 PDF 配套使用,目的是让示例同时包含“原始资料”和“人工整理后的关注点”。
## 背景
- 我们正在验证 `cognee` 是否能把 markdown 和 PDF 一起构造成可检索的知识空间。
- 这次不追求复杂业务场景,只关注最小可运行闭环。
- 智能体框架使用 `LangChain`,底层模型走阿里云百炼的 OpenAI 兼容接口。
## 本次重点
1. `self-attention` 的优势
2. Transformer 的并行计算能力
3. 模型处理长距离依赖的能力
4. `cognee` 是否能把人工备注和论文内容联合起来回答问题
## 成功标准
- 可以完成 `add + cognify`
- 查询结果不是空图谱
- 问题回答能明显结合 PDF 与 markdown
- 通过 `agent_demo.py` 能看到一个完整的最小 agent 查询流程
examples/data/experiment_findings.md
# 实验观察记录
## 目标
这份记录用于补充论文 PDF 中不够显式、但我们希望更容易检索到的验证线索。
## 观察点
1. 本次示例最关注 `self-attention`、`并行计算`、`长距离依赖` 三个主题。
2. 如果检索结果能同时引用论文内容和本文件中的观察点,说明多文档信息已经被联合使用。
3. 与循环网络相比,Transformer 的优势之一是更适合并行化训练。
4. 与单纯只看摘要相比,结合人工整理的 markdown 备注更容易验证检索是否命中重点。
5. 第一轮验证不追求严格评测指标,只关注“能否稳定入库、能否查到、回答是否引用多个来源”。
## 推荐验证点
- 问模型:Transformer 为什么适合并行计算?
- 问模型:这个示例最关注哪三个主题?
- 问模型:论文原文和实验记录之间有哪些互相印证的地方?
examples/data/qa_reference.md
# 问答参考与术语表
## 术语表
- `self-attention`:让序列中的每个位置都可以关注其他位置的信息。
- `parallelism`:并行计算能力,通常意味着训练时更容易同时处理多个 token。
- `long-range dependencies`:长距离依赖,表示模型可以更自然地关联相隔较远的上下文。
## 示例问法
1. Transformer 论文里 self-attention 的核心优势是什么?
2. 论文为什么说这种结构更适合并行计算?
3. 这套示例数据最关注哪些主题?
4. markdown 备注和论文内容之间有哪些一致之处?
5. 如果只看这套示例,第一轮验证成功的标准是什么?
## 补充说明
- 本示例的数据集名称固定为 `aliyun_bailian_demo`。
- 运行顺序必须是先执行 `ingest_demo.py`,再执行 `agent_demo.py`。
- 如果出现 `empty knowledge graph`,通常意味着入库或 `cognify` 没有真正完成。
src/cognee_samples/__init__.py
"""Support modules for the cognee sample scripts."""
src/cognee_samples/agent_cli.py
from __future__ import annotations
from cognee_samples.demo_data import demo_question
def resolve_question(argv: list[str]) -> str:
"""优先使用命令行传入的问题,没有传入时回退到默认问题。"""
if len(argv) > 1 and argv[1].strip():
return argv[1].strip()
return demo_question()
src/cognee_samples/demo_config.py
from __future__ import annotations
import os
from dataclasses import dataclass
from pathlib import Path
@dataclass(frozen=True)
class DemoConfig:
"""示例运行所需的最小配置集合。"""
openai_api_key: str
openai_base_url: str
openai_model: str
openai_embedding_model: str
openai_embedding_endpoint: str
openai_embedding_dimensions: int
openai_embedding_max_tokens: int
cognee_data_dir: Path
def build_demo_config() -> DemoConfig:
"""从环境变量中读取百炼兼容 OpenAI 接口所需配置。"""
openai_api_key = _read_required_env("OPENAI_API_KEY")
openai_base_url = _normalize_openai_base_url(_read_required_env("OPENAI_BASE_URL"))
openai_model = _read_required_env("OPENAI_MODEL")
openai_embedding_model = _read_required_env("OPENAI_EMBEDDING_MODEL")
openai_embedding_endpoint = os.getenv("OPENAI_EMBEDDING_ENDPOINT") or openai_base_url
openai_embedding_dimensions = _read_int_env("OPENAI_EMBEDDING_DIMENSIONS", default=1024)
openai_embedding_max_tokens = _read_int_env("OPENAI_EMBEDDING_MAX_TOKENS", default=8192)
cognee_data_dir = Path(os.getenv("COGNEE_DATA_DIR", ".cognee"))
return DemoConfig(
openai_api_key=openai_api_key,
openai_base_url=openai_base_url,
openai_model=openai_model,
openai_embedding_model=openai_embedding_model,
openai_embedding_endpoint=openai_embedding_endpoint,
openai_embedding_dimensions=openai_embedding_dimensions,
openai_embedding_max_tokens=openai_embedding_max_tokens,
cognee_data_dir=cognee_data_dir,
)
def _read_required_env(name: str) -> str:
"""读取必填环境变量,缺失时给出明确报错。"""
value = os.getenv(name)
if not value:
raise ValueError(f"Missing required environment variable: {name}")
return value
def _read_int_env(name: str, default: int) -> int:
"""读取整数环境变量,缺失时返回默认值。"""
value = os.getenv(name)
if not value:
return default
try:
return int(value)
except ValueError as error:
raise ValueError(f"Environment variable {name} must be an integer") from error
def _normalize_openai_base_url(raw_url: str) -> str:
"""把可能误填成完整路径的 URL 归一化为 base URL。"""
url = raw_url.rstrip("/")
for suffix in ("/chat/completions", "/embeddings"):
if url.endswith(suffix):
return url[: -len(suffix)]
return url
src/cognee_samples/demo_data.py
from __future__ import annotations
from pathlib import Path
def project_root() -> Path:
return Path(__file__).resolve().parents[2]
def demo_data_dir() -> Path:
return project_root() / "examples" / "data"
def sample_markdown_path() -> Path:
return demo_data_dir() / "sample_notes.md"
def sample_pdf_path() -> Path:
return demo_data_dir() / "attention_is_all_you_need.pdf"
def experiment_findings_path() -> Path:
return demo_data_dir() / "experiment_findings.md"
def qa_reference_path() -> Path:
return demo_data_dir() / "qa_reference.md"
def query_examples_path() -> Path:
return project_root() / "examples" / "query_examples.md"
def demo_document_paths() -> list[Path]:
return [
sample_markdown_path(),
experiment_findings_path(),
qa_reference_path(),
sample_pdf_path(),
]
def demo_dataset_name() -> str:
return "aliyun_bailian_demo"
def demo_question() -> str:
return (
"What are the core advantages of self-attention in the Transformer paper, "
"and how do those ideas connect to the markdown notes in this demo?"
)
src/cognee_samples/cognee_runtime.py
from __future__ import annotations
import asyncio
import json
import math
import os
from pathlib import Path
from typing import Any
from urllib.error import HTTPError, URLError
from urllib.request import Request, urlopen
from dotenv import load_dotenv
from cognee_samples.demo_config import DemoConfig, build_demo_config
from cognee_samples.demo_data import demo_dataset_name, demo_document_paths
def load_demo_config() -> DemoConfig:
"""加载 .env,并返回示例脚本统一使用的配置对象。"""
load_dotenv()
return build_demo_config()
def configure_cognee(config: DemoConfig) -> Any:
"""按示例工程的约定初始化 cognee。"""
os.environ.setdefault("ENABLE_BACKEND_ACCESS_CONTROL", "false")
os.environ["OPENAI_EMBEDDING_MAX_TOKENS"] = str(config.openai_embedding_max_tokens)
import cognee
_patch_openai_compatible_embedding_engine()
# 把数据目录固定在项目内,便于重复调试、清理和观察示例状态。
data_root = (config.cognee_data_dir / "data").resolve()
system_root = (config.cognee_data_dir / "system").resolve()
data_root.mkdir(parents=True, exist_ok=True)
system_root.mkdir(parents=True, exist_ok=True)
cognee.config.data_root_directory(str(data_root))
cognee.config.system_root_directory(str(system_root))
cognee.config.set_llm_provider("openai")
cognee.config.set_llm_api_key(config.openai_api_key)
cognee.config.set_llm_model(_normalize_litellm_model(config.openai_model))
cognee.config.set_llm_endpoint(config.openai_base_url)
cognee.config.set_llm_config({"llm_args": {"extra_body": {"enable_thinking": False}}})
cognee.config.set_embedding_provider("openai_compatible")
cognee.config.set_embedding_api_key(config.openai_api_key)
cognee.config.set_embedding_model(config.openai_embedding_model)
cognee.config.set_embedding_dimensions(config.openai_embedding_dimensions)
cognee.config.set_embedding_endpoint(config.openai_embedding_endpoint)
return cognee
def _normalize_litellm_model(model: str) -> str:
"""确保 LiteLLM 能识别 provider 前缀。"""
if "/" in model:
return model
return f"openai/{model}"
def build_protocol_debug_report(config: DemoConfig) -> str:
"""输出当前 LLM 与 embedding 协议格式,便于排查。"""
llm_endpoint = _openai_chat_completions_url(config.openai_base_url)
embedding_is_raw_dashscope = _is_dashscope_raw_embedding_endpoint(
config.openai_embedding_endpoint
)
embedding_endpoint = (
config.openai_embedding_endpoint
if embedding_is_raw_dashscope
else _openai_embeddings_url(config.openai_embedding_endpoint)
)
llm_payload = {
"model": config.openai_model,
"messages": [{"role": "user", "content": "ping"}],
"max_tokens": 1,
"temperature": 0,
}
if embedding_is_raw_dashscope:
embedding_payload: dict[str, Any] = {
"model": config.openai_embedding_model,
"input": {"texts": ["连通性探测"]},
"parameters": {
"output_type": "dense",
"dimension": config.openai_embedding_dimensions,
},
}
else:
embedding_payload = {
"model": config.openai_embedding_model,
"input": ["连通性探测"],
"encoding_format": "float",
"dimensions": config.openai_embedding_dimensions,
}
headers = {
"Authorization": f"Bearer {_redact_api_key(config.openai_api_key)}",
"Content-Type": "application/json",
}
return "\n".join(
[
"=== 协议诊断信息(已脱敏)===",
f"LLM endpoint: {llm_endpoint}",
f"Embedding endpoint: {embedding_endpoint}",
f"Embedding 模式: {'dashscope_raw' if embedding_is_raw_dashscope else 'openai_compatible'}",
"LLM headers:",
json.dumps(headers, ensure_ascii=False, indent=2),
"LLM payload:",
json.dumps(llm_payload, ensure_ascii=False, indent=2),
"Embedding headers:",
json.dumps(headers, ensure_ascii=False, indent=2),
"Embedding payload:",
json.dumps(embedding_payload, ensure_ascii=False, indent=2),
]
)
async def run_endpoint_diagnostics(config: DemoConfig) -> str:
"""执行 LLM 与 embedding endpoint 探测,输出结果摘要。"""
llm_result = await asyncio.to_thread(_probe_llm_endpoint, config)
embedding_result = await asyncio.to_thread(_probe_embedding_endpoint, config)
auto_skip_note = _maybe_enable_skip_connection_test(llm_result, embedding_result)
return "\n".join(
[
"=== 连通性探测结果 ===",
_format_probe_result("LLM", llm_result),
_format_probe_result("Embedding", embedding_result),
auto_skip_note,
]
)
def _format_probe_result(name: str, result: dict[str, Any]) -> str:
status = "OK" if result["ok"] else "FAILED"
return (
f"[{name}] {status}\n"
f"- endpoint: {result['endpoint']}\n"
f"- detail: {result['detail']}\n"
f"- preview: {result['preview']}"
)
def _maybe_enable_skip_connection_test(
llm_result: dict[str, Any], embedding_result: dict[str, Any]
) -> str:
if not (llm_result.get("ok") and embedding_result.get("ok")):
return "自动处理: 未启用 COGNEE_SKIP_CONNECTION_TEST(探测未全部通过)。"
os.environ["COGNEE_SKIP_CONNECTION_TEST"] = "true"
return "自动处理: 已设置 COGNEE_SKIP_CONNECTION_TEST=true,跳过 cognee 内置探测。"
def _probe_llm_endpoint(config: DemoConfig) -> dict[str, Any]:
endpoint = _openai_chat_completions_url(config.openai_base_url)
payload = {
"model": config.openai_model,
"messages": [{"role": "user", "content": "ping"}],
"max_tokens": 1,
"temperature": 0,
}
result = _post_json(endpoint=endpoint, payload=payload, api_key=config.openai_api_key)
if not result["ok"]:
return result
try:
response_json = json.loads(result["body"])
except json.JSONDecodeError:
return {
"ok": False,
"endpoint": endpoint,
"detail": "LLM 响应不是合法 JSON。",
"preview": _truncate(result["body"], 300),
}
choices = response_json.get("choices", [])
message = ""
if choices and isinstance(choices, list):
message = str(choices[0].get("message", {}))
return {
"ok": True,
"endpoint": endpoint,
"detail": "LLM endpoint 可达并返回 choices。",
"preview": _truncate(message or result["body"], 300),
}
def _probe_embedding_endpoint(config: DemoConfig) -> dict[str, Any]:
if _is_dashscope_raw_embedding_endpoint(config.openai_embedding_endpoint):
endpoint = config.openai_embedding_endpoint
payload: dict[str, Any] = {
"model": config.openai_embedding_model,
"input": {"texts": ["连通性探测"]},
"parameters": {
"output_type": "dense",
"dimension": config.openai_embedding_dimensions,
},
}
result = _post_json(endpoint=endpoint, payload=payload, api_key=config.openai_api_key)
if not result["ok"]:
return result
try:
response_json = json.loads(result["body"])
except json.JSONDecodeError:
return {
"ok": False,
"endpoint": endpoint,
"detail": "Embedding 响应不是合法 JSON。",
"preview": _truncate(result["body"], 300),
}
embeddings = response_json.get("output", {}).get("embeddings", [])
vector_size = len(embeddings[0].get("embedding", [])) if embeddings else 0
return {
"ok": vector_size > 0,
"endpoint": endpoint,
"detail": f"DashScope embedding 可用,向量维度={vector_size}" if vector_size > 0 else "响应缺少 output.embeddings。",
"preview": _truncate(json.dumps(response_json, ensure_ascii=False), 300),
}
endpoint = _openai_embeddings_url(config.openai_embedding_endpoint)
payload = {
"model": config.openai_embedding_model,
"input": ["连通性探测"],
"encoding_format": "float",
"dimensions": config.openai_embedding_dimensions,
}
result = _post_json(endpoint=endpoint, payload=payload, api_key=config.openai_api_key)
if not result["ok"]:
return result
try:
response_json = json.loads(result["body"])
except json.JSONDecodeError:
return {
"ok": False,
"endpoint": endpoint,
"detail": "Embedding 响应不是合法 JSON。",
"preview": _truncate(result["body"], 300),
}
data = response_json.get("data", [])
vector_size = len(data[0].get("embedding", [])) if data else 0
return {
"ok": vector_size > 0,
"endpoint": endpoint,
"detail": f"OpenAI-compatible embedding 可用,向量维度={vector_size}" if vector_size > 0 else "响应缺少 data[0].embedding。",
"preview": _truncate(json.dumps(response_json, ensure_ascii=False), 300),
}
def _post_json(endpoint: str, payload: dict[str, Any], api_key: str) -> dict[str, Any]:
request = Request(
endpoint,
data=json.dumps(payload).encode("utf-8"),
headers={
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
},
method="POST",
)
try:
with urlopen(request, timeout=20) as response:
body = response.read().decode("utf-8", errors="ignore")
return {"ok": True, "endpoint": endpoint, "body": body}
except HTTPError as error:
detail = error.read().decode("utf-8", errors="ignore")
return {
"ok": False,
"endpoint": endpoint,
"detail": f"HTTP {error.code}",
"preview": _truncate(detail, 300),
}
except URLError as error:
return {
"ok": False,
"endpoint": endpoint,
"detail": "网络连接失败",
"preview": _truncate(str(error), 300),
}
except TimeoutError as error:
return {
"ok": False,
"endpoint": endpoint,
"detail": "请求超时",
"preview": _truncate(str(error), 300),
}
def _openai_chat_completions_url(base_url: str) -> str:
normalized = base_url.rstrip("/")
if normalized.endswith("/chat/completions"):
return normalized
if normalized.endswith("/v1"):
return f"{normalized}/chat/completions"
return f"{normalized}/v1/chat/completions"
def _openai_embeddings_url(base_url: str) -> str:
normalized = base_url.rstrip("/")
if normalized.endswith("/embeddings"):
return normalized
if normalized.endswith("/v1"):
return f"{normalized}/embeddings"
return f"{normalized}/v1/embeddings"
def _redact_api_key(api_key: str) -> str:
if len(api_key) <= 8:
return "****"
return f"{api_key[:4]}...{api_key[-4:]}"
def _truncate(text: str, limit: int) -> str:
if len(text) <= limit:
return text
return f"{text[:limit]}..."
def _patch_openai_compatible_embedding_engine() -> None:
"""为 cognee 的 OpenAI-compatible embedding 引擎补齐百炼兼容逻辑。"""
try:
from cognee.infrastructure.databases.vector.embeddings.OpenAICompatibleEmbeddingEngine import (
OpenAICompatibleEmbeddingEngine,
)
except Exception:
return
if getattr(OpenAICompatibleEmbeddingEngine, "_cognee_samples_patch_applied", False):
return
original_init = OpenAICompatibleEmbeddingEngine.__init__
original_embed_text = OpenAICompatibleEmbeddingEngine.embed_text
def patched_init(
self,
model: str | None = "default",
dimensions: int = 3072,
endpoint: str | None = "http://localhost:8080",
api_key: str | None = "no-key-required",
batch_size: int = 36,
) -> None:
original_init(
self,
model=model,
dimensions=dimensions,
endpoint=endpoint,
api_key=api_key,
batch_size=batch_size,
)
self.max_completion_tokens = int(os.getenv("OPENAI_EMBEDDING_MAX_TOKENS", "8192"))
self.tokenizer = getattr(self, "tokenizer", None)
self._dashscope_raw_embedding_endpoint = (
endpoint if endpoint and _is_dashscope_raw_embedding_endpoint(endpoint) else None
)
async def patched_embed_text(self, text: list[str]) -> list[list[float]]:
raw_endpoint = getattr(self, "_dashscope_raw_embedding_endpoint", None)
if not raw_endpoint:
return await original_embed_text(self, text)
return await _embed_text_with_dashscope_endpoint(
texts=text,
model=self.model,
endpoint=raw_endpoint,
api_key=self.api_key,
dimensions=getattr(self, "dimensions", None),
batch_size=getattr(self, "batch_size", 10),
)
OpenAICompatibleEmbeddingEngine.__init__ = patched_init
OpenAICompatibleEmbeddingEngine.embed_text = patched_embed_text
OpenAICompatibleEmbeddingEngine._cognee_samples_patch_applied = True
def _is_dashscope_raw_embedding_endpoint(endpoint: str) -> bool:
"""判断是否使用百炼原生 embedding 接口。"""
normalized_endpoint = endpoint.rstrip("/")
return "/services/embeddings/" in normalized_endpoint
async def _embed_text_with_dashscope_endpoint(
texts: list[str],
model: str,
endpoint: str,
api_key: str,
dimensions: int | None,
batch_size: int,
) -> list[list[float]]:
"""调用百炼原生 embedding endpoint。"""
embeddings: list[list[float]] = []
chunk_size = max(1, min(batch_size, 10))
for chunk_start in range(0, len(texts), chunk_size):
chunk = texts[chunk_start : chunk_start + chunk_size]
try:
chunk_embeddings = await asyncio.to_thread(
_post_dashscope_embeddings,
texts=chunk,
model=model,
endpoint=endpoint,
api_key=api_key,
dimensions=dimensions,
)
except RuntimeError as error:
if not _is_dashscope_input_too_long_error(error):
raise
if len(chunk) > 1:
mid = math.ceil(len(chunk) / 2)
left_embeddings, right_embeddings = await asyncio.gather(
_embed_text_with_dashscope_endpoint(
texts=chunk[:mid],
model=model,
endpoint=endpoint,
api_key=api_key,
dimensions=dimensions,
batch_size=batch_size,
),
_embed_text_with_dashscope_endpoint(
texts=chunk[mid:],
model=model,
endpoint=endpoint,
api_key=api_key,
dimensions=dimensions,
batch_size=batch_size,
),
)
chunk_embeddings = left_embeddings + right_embeddings
elif len(chunk) == 1:
text = chunk[0]
split_at = len(text) // 3
if split_at == 0:
raise RuntimeError("DashScope embedding 文本过长,且无法继续切分。") from error
left_text = text[: split_at * 2]
right_text = text[split_at:]
(left_embedding,), (right_embedding,) = await asyncio.gather(
_embed_text_with_dashscope_endpoint(
texts=[left_text],
model=model,
endpoint=endpoint,
api_key=api_key,
dimensions=dimensions,
batch_size=batch_size,
),
_embed_text_with_dashscope_endpoint(
texts=[right_text],
model=model,
endpoint=endpoint,
api_key=api_key,
dimensions=dimensions,
batch_size=batch_size,
),
)
chunk_embeddings = [
[
(left_value + right_value) / 2
for left_value, right_value in zip(left_embedding, right_embedding)
]
]
else:
raise
embeddings.extend(chunk_embeddings)
return embeddings
def _is_dashscope_input_too_long_error(error: RuntimeError) -> bool:
error_text = str(error).lower()
return "range of input length should be [1, 8192]" in error_text
def _post_dashscope_embeddings(
texts: list[str],
model: str,
endpoint: str,
api_key: str,
dimensions: int | None,
) -> list[list[float]]:
"""通过 HTTP 请求百炼原生 embedding 接口。"""
parameters: dict[str, Any] = {"output_type": "dense"}
if dimensions:
parameters["dimension"] = dimensions
payload = {
"model": model,
"input": {"texts": texts},
"parameters": parameters,
}
request = Request(
endpoint,
data=json.dumps(payload).encode("utf-8"),
headers={
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
},
method="POST",
)
try:
with urlopen(request, timeout=30) as response:
response_payload = json.loads(response.read().decode("utf-8"))
except HTTPError as error:
detail = error.read().decode("utf-8", errors="ignore")
raise RuntimeError(f"DashScope embedding 请求失败:HTTP {error.code} {detail}") from error
except URLError as error:
raise RuntimeError("DashScope embedding 请求失败:无法连接到 embedding endpoint。") from error
output = response_payload.get("output", {})
embedding_items = output.get("embeddings")
if not embedding_items:
raise RuntimeError("DashScope embedding 响应缺少 output.embeddings。")
sorted_items = sorted(embedding_items, key=lambda item: item.get("text_index", 0))
return [item["embedding"] for item in sorted_items]
def ensure_demo_inputs_exist() -> list[Path]:
"""确认所有示例文档都存在,避免 cognify 在空输入下运行。"""
document_paths = demo_document_paths()
missing_paths = [str(path) for path in document_paths if not path.exists()]
if missing_paths:
joined = ", ".join(missing_paths)
raise FileNotFoundError(f"Missing demo input files: {joined}")
return document_paths
def build_runtime_help_message(error: Exception) -> str:
"""把常见运行时异常转换成更易理解的中文提示。"""
error_text = str(error)
if "socksio" in error_text.lower():
return (
"检测到当前环境启用了 SOCKS 代理,但运行环境中没有安装 `socksio`。\n"
"如果你依赖 SOCKS 代理,请安装支持:`uv add 'httpx[socks]'`。\n"
"如果你不需要代理,请临时清理 `ALL_PROXY` / `HTTP_PROXY` / `HTTPS_PROXY` 后重试。"
)
if "empty knowledge graph" in error_text.lower():
return "当前知识图谱为空。请先成功执行 examples/ingest_demo.py,再运行查询脚本。"
if "Could not set lock on file" in error_text:
return (
"检测到图数据库文件锁冲突,通常是上一次运行未正常退出或有并发进程占用。\n"
"请先关闭正在运行的 ingest/agent 进程,再执行:\n"
"1) lsof .cognee/system/databases/cognee_graph_kuzu\n"
"2) rm -rf .cognee/system/databases/cognee_graph_kuzu*\n"
"3) 重新运行 examples/ingest_demo.py"
)
if "No static resource" in error_text and "/chat/completions/chat/completions" in error_text:
return (
"检测到 OPENAI_BASE_URL 配置成了完整 chat/completions 路径,导致 SDK 再次拼接路径。\n"
"请把 OPENAI_BASE_URL 改为 base URL,例如:\n"
"https://dashscope.aliyuncs.com/compatible-mode/v1"
)
if "LLM Provider NOT provided" in error_text:
return (
"检索阶段的 litellm 无法识别模型 provider。\n"
"已在运行时自动把模型名转换为 openai/<model> 形式,请更新后重试。"
)
if "tool_choice parameter does not support being set to required" in error_text:
return (
"当前模型处于 thinking 模式,和 agent 的 tool_choice=required 冲突。\n"
"已在 agent_demo 中设置 enable_thinking=false,请更新后重试。"
)
if "LLM connection test timed out" in error_text:
return (
"LLM 连接测试超时。请先检查 OPENAI_BASE_URL 与 OPENAI_MODEL 是否可用,\n"
"并观察 ingest_demo 开头打印的协议与连通性探测结果。\n"
"如果你需要先跳过探测,可临时设置 COGNEE_SKIP_CONNECTION_TEST=true。"
)
return f"运行失败:{error_text}"
async def ingest_demo_dataset() -> str:
"""把示例 markdown 与 PDF 写入单一数据集,并执行 cognify。"""
config = load_demo_config()
cognee = configure_cognee(config)
document_paths = ensure_demo_inputs_exist()
dataset_name = demo_dataset_name()
await cognee.add([str(path) for path in document_paths], dataset_name=dataset_name)
await cognee.cognify(datasets=[dataset_name])
return dataset_name
async def search_demo_dataset(question: str) -> list[Any]:
"""在已构建的数据集上执行查询,供 agent 工具调用。"""
config = load_demo_config()
cognee = configure_cognee(config)
dataset_name = demo_dataset_name()
return await cognee.search(query_text=question, datasets=[dataset_name])
3.8 常见问题与排错
结合当前项目实现和 README,总结几类最常见的问题如下。
1. KeyError: Could not automatically map text-embedding-v4 to a tokeniser
最常见原因是百炼 embedding 模型名无法被 tiktoken 自动识别。当前项目已经通过两层方式规避:
- embedding provider 使用
openai_compatible - 对
OpenAICompatibleEmbeddingEngine做运行时 patch
如果你仍然看到这个错误,通常说明本地运行的不是当前这份代码,或者环境仍在使用旧脚本。
2. Search attempt on an empty knowledge graph
这基本说明知识图谱还没真正构建完成。优先检查:
- 是否先运行了
examples/ingest_demo.py cognify是否执行成功.cognee是否被清理过
常用恢复步骤:
rm -rf .cognee
env UV_CACHE_DIR=/tmp/uv-cache uv run --python 3.12 python examples/ingest_demo.py
env UV_CACHE_DIR=/tmp/uv-cache uv run --python 3.12 python examples/agent_demo.py
3. Missing required environment variable
说明 .env 未正确填写,或者当前运行环境没有加载到 .env。至少需要确认下面几个字段:
OPENAI_API_KEYOPENAI_BASE_URLOPENAI_MODELOPENAI_EMBEDDING_MODEL
4. Using SOCKS proxy, but the 'socksio' package is not installed
这不是 cognee 本身的问题,而是环境代理配置导致的。可以二选一:
uv add "httpx[socks]"
或者:
env -u ALL_PROXY -u HTTP_PROXY -u HTTPS_PROXY UV_CACHE_DIR=/tmp/uv-cache uv run --python 3.12 python examples/ingest_demo.py
5. Kuzu 锁冲突
如果看到类似 Could not set lock on file 的报错,说明上次进程可能未正常退出,或者有并发进程占用了图数据库文件。先确认没有其他进程,再执行:
lsof .cognee/system/databases/cognee_graph_kuzu
rm -rf .cognee/system/databases/cognee_graph_kuzu*
然后重新执行入库流程。
4. 总结
cognee 值得关注的地方,不只是“能做向量检索”,而是它试图把文档来源、语义检索和知识图谱这三层能力组合成一个更接近“记忆系统”的数据层。