- Published on
本体论到底是什么:用 FCKG 电影奖项图谱做一次形象化理解
- Authors

- Name
- Shoukai Huang

Ontology 形象化理解(Photo by Caroline Badran on Unsplash)
目录
- 目录
- 先看权威定义
- 先看一张电影奖项世界地图
- Class / Concept:这个世界里有什么类型
- Instance / Individual:具体发生的那个对象
- Relationship / Property:对象之间的动词
- Constraint / Shape:这张地图的交通规则
- URI / Identifier:对象的地址系统
- Alignment / Controlled Vocabulary:不同叫法背后的同一含义
- Inference:按规则自动想明白
- 再看 FCKG 的四层栈
- 重新回顾:本体论到底包含什么
- 本体论不是什么
- 为什么这对 AI 重要
- 结尾
- 参考资料
如果只用一句话理解本体论:
本体论是一份可执行的领域说明书。
它不是一份普通文档,也不只是术语表。它要回答的是:在这个领域里,哪些东西存在?它们属于什么类型?它们之间能发生什么关系?什么数据算合法?同一个对象如何被识别?哪些事实可以根据规则自动推出?
更形象一点说,如果知识图谱是一张地图,本体论就像地图背后的图例、道路规则、地址系统和推理规则。
地图上画了很多点和线,但你需要图例告诉你:什么是城市,什么是河流,什么是火车站,什么是高速公路。你还需要交通规则告诉你:哪些路能通行,哪些路是单行线,哪些连接不合法。你也需要地址系统告诉你:两个名字相似的地方是不是同一个地方。
技术系统里的 ontology 做的就是这件事。
为了让这个概念不漂在空中,我们用一个开源项目做例子:FCKG。它是 Steve Hedden 做的 Film Club Knowledge Graph,一个围绕电影奖项、提名、人物、电影和预测模型构建的 RDF 知识图谱项目。
先看权威定义
知识工程里最经典的定义来自 Thomas Gruber:ontology 是 "an explicit specification of a conceptualization"。可以拆成两半理解:
- conceptualization:我们如何理解一个领域。
- explicit specification:把这种理解明确写出来。
也就是说,ontology 不是脑子里的模糊共识,而是把共识变成明确规范。
W3C 的 OWL 2 Primer 也给了一个很工程化的角度:OWL 是一种带有形式化语义的 ontology language,用来表示 things、groups of things,以及 things 之间的 relations。换成人话:它不是只列名词,而是表达"有什么东西、哪些东西属于一类、它们之间是什么关系"。
RDF 则提供最小事实单位。W3C 对 RDF graph 的解释是:RDF graph 由 triples 构成。一个 triple 就是:
subject predicate object
例如:
某个提名 hasFilm 某部电影
某个提名 hasNominee 某个人
某个提名 hasCeremony 某届颁奖礼
SHACL 再补上另一块:它是描述和验证 RDF graph 的约束语言。也就是说,它可以规定"某类节点必须有哪些属性"、"这个属性的值必须是什么类型"、"最多只能出现几次"。
把这些权威定义压缩成更易记的话:
本体论 = 把一个领域的共同理解,写成机器可处理的概念、关系和规则。
如果再结合 ontology-based data model 的总结,它还可以被写得更工程化一点:
Ontology-based model =
业务概念
+ 显式声明的关系
+ 编码业务含义的约束
+ 受治理的词汇表
这句话里的重点是"业务含义"。
数据库 schema 更关心数据怎么存;ontology 更关心数据是什么意思。它不是替代数据库、数仓或存储系统,而是位于物理 schema 之上的语义结构,把原始数据翻译成跨分析、应用和 AI 系统都能一致理解的表示。
所以,ontology 的核心范式不是围绕存储组织数据,而是围绕含义组织数据。
接下来我们用 FCKG 把这些词一个个落地。
先看一张电影奖项世界地图
FCKG 提供了一个交互式 ontology 图。先不用急着看每条边的细节,只看这张图里有哪些"东西":
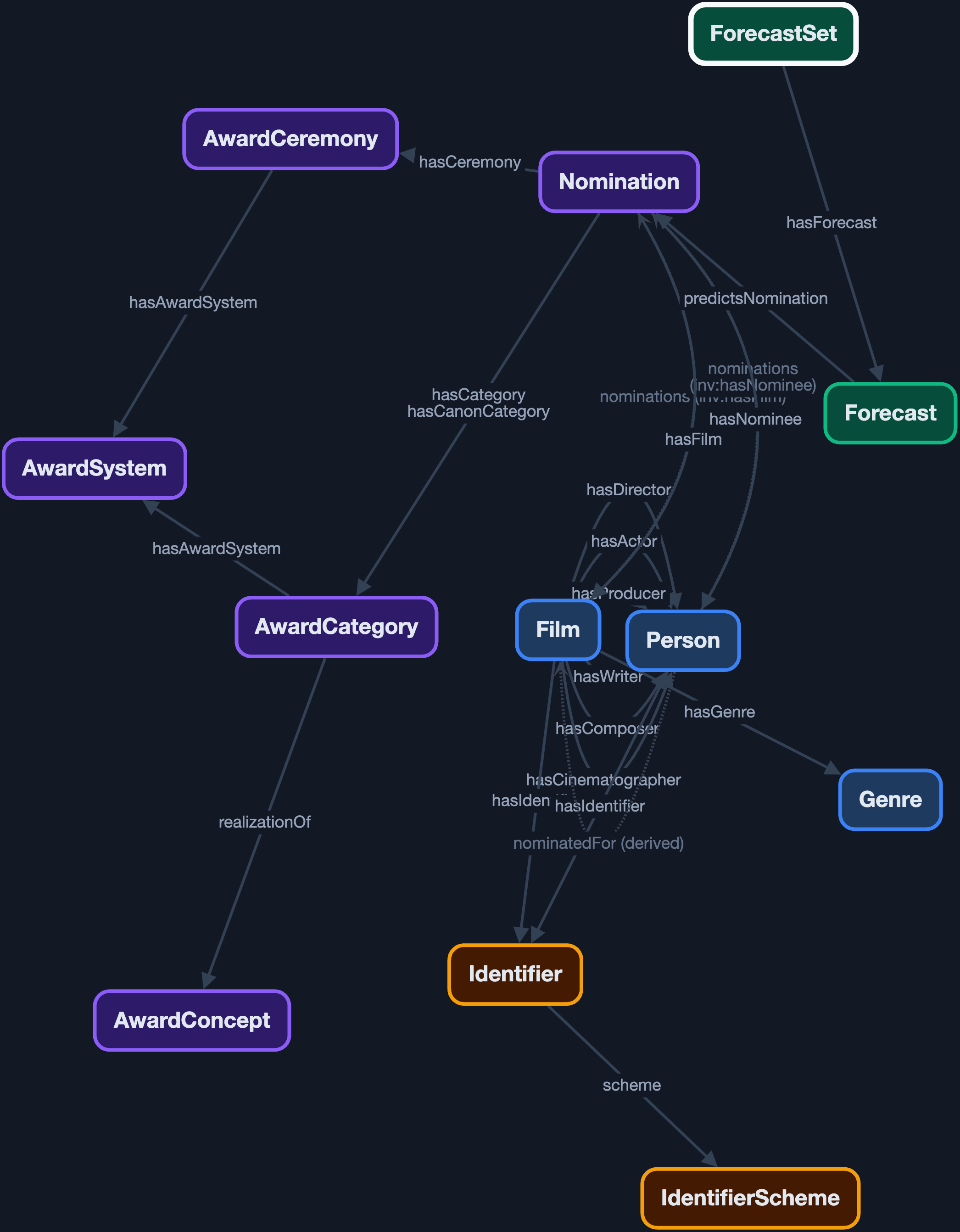
FCKG ontology map:电影奖项图谱中的核心类型、关系与标识系统
你会看到一些框:
FilmPersonNominationAwardSystemAwardCeremonyAwardCategoryAwardConceptIdentifierForecastSetForecast
这就是一个领域被本体化之后的第一层样子。
电影奖项世界本来是混杂的:电影、导演、演员、奖项、类别、年份、预测结果、外部 ID 全搅在一起。本体论做的第一步,是把这个世界拆成清楚的对象类型。
这和我们看地图很像。地图不是先告诉你"北京到上海有一条线",而是先约定:圆点代表城市,蓝线代表河流,黑线代表铁路,红线代表高速。
Ontology 也是这样。它先告诉机器:这个领域里有哪些类型的东西。
Class / Concept:这个世界里有什么类型
Class 或 Concept,可以理解成"这个领域承认的对象类型"。
在 FCKG 里:
Film是电影。Person是电影相关人物。AwardSystem是奖项体系,比如 Oscars、BAFTA、SAG。AwardCategory是奖项体系中的具体类别。Nomination是一次提名。Forecast是一次预测。
这里最容易误解的一点是:Class 不是数据库表名。
数据库表更多是存储结构,常常受系统实现影响。Ontology 里的 Class 关注的是领域含义。它问的是:在我们讨论的世界里,哪些对象值得作为一类东西被稳定识别?
Concept 是一等业务实体,不是表。放在 FCKG 里,Film 不是某个 CSV 表,Person 也不是某个数据源里的姓名列。它们是电影奖项世界中被共同承认的对象类型。
FCKG 里最有启发的类是 Nomination。
如果只凭直觉,很多人会先建 Film 和 Person。电影和人当然重要,但这个项目真正关心的是奖项预测。预测的对象不是一部电影本身,也不是某个人本身,而是"某部电影或某个人在某一年某个类别里获得的一次提名,并且最后是否获奖"。
所以 Nomination 被建成核心类。
这说明本体建模不是把所有名词都列出来,而是找出最能承载问题的对象类型。
Instance / Individual:具体发生的那个对象
Class 定义的是类型,Instance 或 Individual 才是具体对象。
Film 是类型,某一部电影是实例。Person 是类型,某一位导演是实例。Nomination 是类型,"某部电影在某届奥斯卡最佳影片中的那次提名"才是实例。
可以用一个生活类比:
- "户型图"定义房间类型:卧室、客厅、厨房。
- "你家这间卧室"是具体实例。
Ontology 更像户型图,不是具体房间清单。实例数据才是具体房间。
FCKG 的 movieontology.ttl 定义了这些类型和关系;data/instances/ 里的 TTL 文件填充具体实例,比如 Oscar nominations、BAFTA nominations、films、people。
这一点很重要:ontology 和 knowledge graph 不是同一个东西。
Ontology 定义世界的结构。
Instance data 填充这个世界。
Knowledge graph 是结构和实例结合之后形成的图。
没有 ontology,实例数据只是很多点。没有实例数据,ontology 只是空的结构。两者结合,才有可查询、可推理的知识图谱。
Relationship / Property:对象之间的动词
如果 Class 是名词,Relationship / Property 就是动词。
本体论真正有价值的地方,往往不只是定义名词,而是定义这些名词之间能发生什么关系。
在 FCKG 里,一个 Nomination 可以有这些关系:
Nomination hasFilm Film
Nomination hasNominee Person
Nomination hasCeremony AwardCeremony
Nomination hasCategory AwardCategory
这些关系都有方向和语义。
Nomination hasFilm Film 的意思不是"提名和电影有点关系",而是"这次提名对应哪部电影"。Nomination hasNominee Person 的意思也不是"提名旁边有个人名",而是"这个人是这次提名的 nominee"。
这就是 declared relationships 的含义:关系不是从 foreign key、join 条件或字段名里临时推断出来,而是在 ontology 里被显式声明和命名。
如果用传统表结构思维,你可能会写:
nominations.film_id = films.id
但这个 join 条件并没有告诉系统"这部电影是被提名作品"。Ontology 要表达的是:
Nomination hasFilm Film
前者是技术连接,后者是语义关系。
很多低质量知识图谱的问题就在这里:点很多,边也很多,但边的名字都很模糊,最后全变成 relatedTo。一旦所有东西都只是"相关",机器就不知道该怎么推理,人也不知道这条边到底能不能用于分析。
好的 ontology 会尽量把关系命名清楚。
从形象上看,Relationship 就像地图上的道路。但它不是随便画一条线,而是标明这条线是什么路、从哪里到哪里、表达什么关系。
Constraint / Shape:这张地图的交通规则
只有对象和关系还不够。
如果任何对象都能随便连任何对象,图谱很快就会变成一团线。你需要规则:哪些关系必须存在,哪些关系只能出现一次,哪些值必须是数字,哪些值必须是布尔值。
这就是 Constraint / Shape 的作用。
W3C 的 SHACL 就是用来描述和验证 RDF graph 的约束语言。在 FCKG 里,movieontology.ttl 使用了 SHACL NodeShape 和 PropertyShape。
例如,一个 Nomination 应该连接到一个 ceremony。winner 应该是 boolean。hasFilm 最多对应一部 Film。年份应该是年份类型,不应该写成任意字符串。
但约束不只是"字段校验"。
再进一步看,Business Constraints 表达的是:在特定业务上下文中,哪些关系、指标和解读有效。它可以表达 cardinality(一对一/一对多)、optionality(必需/可选)、validity condition(有效条件)、classification rule(分类规则),甚至 access restriction(访问限制)。
换到 FCKG 里,winner 为什么必须是 boolean?因为预测任务最终需要知道一次 nomination 是否获奖。hasCeremony 为什么应该存在?因为没有 ceremony,提名就失去时间锚点,跨年份比较会变得不可靠。
这些规则看似琐碎,但工程价值很大。
没有约束,错误数据会悄悄进入图谱。比如某个提名没有 ceremony,某个 winner 写成了 "yes maybe",某个提名连了三部电影。模型或 Agent 后面仍然能跑,但它是在错误世界上跑。
Shape 就像交通规则。地图上可以画路,但交通规则规定了哪些路能走、哪些连接不合法、哪些信息必须补齐。
URI / Identifier:对象的地址系统
知识图谱里最容易出问题的,不是没有数据,而是同一个对象被当成多个对象。
一个人可能在不同数据源里有不同写法。一个电影可能在 IMDb、TMDB、Wikidata 中都有 ID。一个奖项类别在不同系统里可能叫法不同。
所以 ontology 和知识图谱需要稳定的标识系统。
在 RDF 世界中,URI 可以理解成对象的地址。FCKG 里,Film 和 Person 都有自己的 URI。除此之外,它还把 IMDb、TMDB、Wikidata ID 作为外部标识符保存下来。
这像什么?
像身份证和门牌号。
如果没有身份证,你很难确定两个名字相同的人是不是同一个人。如果没有门牌号,你很难确认两个地址描述是不是同一个地方。如果没有稳定 URI,图谱里的"同一部电影"也会在不同文件、不同奖项系统、不同外部 API 中裂成多个节点。
FCKG 的 README 里强调,films 和 people 是跨奖项系统共享的。Oscar、BAFTA、SAG 等 nomination 文件引用同一套 Film 和 Person URI。这样,一个人既出现在 Oscar 数据里,又出现在 BAFTA 数据里,图谱仍然知道这是同一个节点。
这是知识图谱连通性的基础。
Alignment / Controlled Vocabulary:不同叫法背后的同一含义
Identifier 解决"同一个对象是谁"。
Alignment 解决另一个问题:"不同名字是不是同一个含义"。
FCKG 里最好的例子是 AwardConcept。
不同奖项系统有不同类别名称。奥斯卡有 Best Actor,SAG 有 Outstanding Performance by a Male Actor in a Leading Role,BAFTA 也有自己的 Best Actor。它们不是同一个字符串,但在建模时经常需要被理解成同一类成就:最佳男主角。
如果没有 ontology,系统只能靠字符串匹配或临时映射表。这样很脆弱:换一个奖项系统,或者类别名字稍微变化,代码就要补规则。
FCKG 的做法是引入 AwardConcept。
AwardCategory 可以通过 realizationOf 指向一个抽象的 AwardConcept。这样,不同系统里的类别名称,可以被声明为同一个概念的不同实现。
这就像一张受治理的翻译词典。
| 现实中的不同叫法 | 本体中的统一含义 |
|---|---|
| Oscar Best Actor | Best Male Lead Actor 概念 |
| SAG Male Actor in a Leading Role | Best Male Lead Actor 概念 |
| BAFTA Best Actor | Best Male Lead Actor 概念 |
这一步非常关键。
因为很多 AI 和数据系统的错误,不是不会算,而是不知道两个词到底是不是同一个意思。Ontology 的价值,就是把这种"大家心里知道但代码不知道"的含义显式写出来。
这也是 governed vocabulary 的意义:定义不是散落在每个查询、脚本和报表里,而是共享、版本化、可复用。业务定义变化时,应尽量在模型层更新一次,让下游系统继承,而不是让每个消费者各自修补。
Inference:按规则自动想明白
本体论不只是存储定义,还可以支持推理。
推理不是神秘能力。它更像按规则自动补全结论。
生活里也有类似规则:
如果 A 是 B 的父亲,
如果 C 是 A 的兄弟,
那么 C 是 B 的叔叔。
只要前两个事实成立,第三个事实就不需要手写,可以推出来。
FCKG 里也有类似结构。假设图里有:
Nomination_X hasNominee Person_Ryan_Coogler
Nomination_X hasFilm Film_Sinners
那么通过规则可以推出:
Person_Ryan_Coogler nominatedFor Film_Sinners
也可以通过 inverse path 推出:
Film_Sinners hasNomination Nomination_X
Person_Ryan_Coogler hasNomination Nomination_X
这类推理的价值在于减少重复存储。
如果一个事实可以由已有事实和规则稳定推出,就不需要在多个地方手动维护。否则你会遇到同步问题:一个文件说 Ryan Coogler 有这个 nomination,另一个文件忘了更新,第三个脚本又推了一个不同结果。
Ontology 把可推导关系写成结构,系统就可以自动保持一致。
再看 FCKG 的四层栈
有了上面的概念,再看 FCKG 的整体图会更清楚:
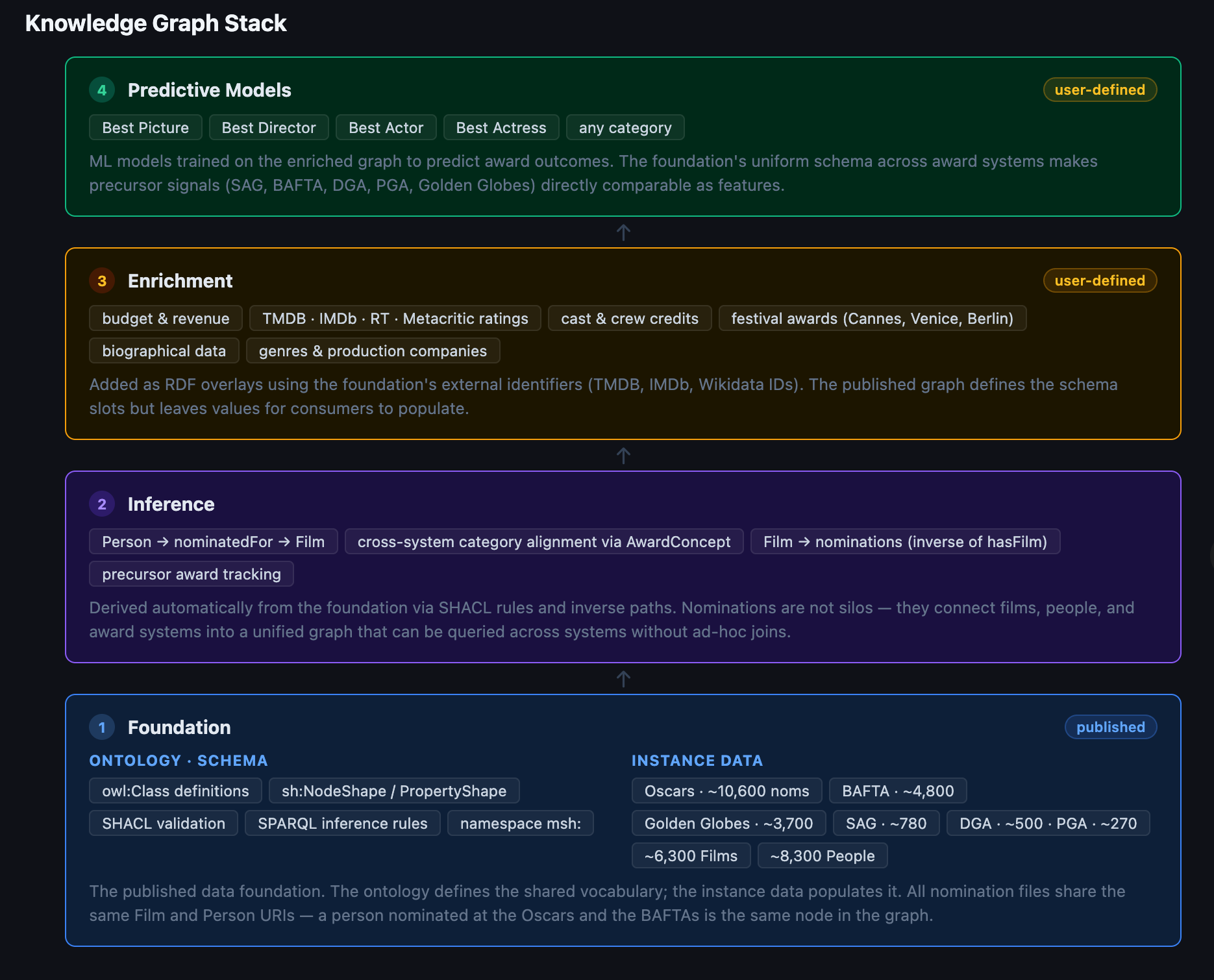
FCKG knowledge graph stack:从 ontology foundation 到 inference、enrichment 和 predictive models 的四层结构
这张图可以按四层理解:
- Foundation:ontology schema + instance data。
- Inference:根据规则和反向关系推出新事实。
- Enrichment:通过 IMDb、TMDB、Wikidata 等 ID 扩展外部数据。
- Predictive Models:在 enriched graph 上训练模型,输出预测。
本文真正关心的是第一层和第二层。
第三层和第四层当然有用,但它们依赖前两层。如果没有 ontology 定义 Film、Person、Nomination、AwardCategory、AwardConcept,后面的 enrichment 不知道数据该挂到哪里,模型也很难知道哪些特征可以跨系统比较。
这就是本体论的位置:它不是应用层炫技,而是底座。
重新回顾:本体论到底包含什么
现在回到最开始的问题:本体论到底是什么?
可以用这张表记住:
| 你要问的问题 | 本体论里的概念 | FCKG 里的例子 | 形象类比 |
|---|---|---|---|
| 这个世界有哪些类型? | Class / Concept | Film、Person、Nomination | 地图图例 |
| 具体有哪些对象? | Instance / Individual | 某部电影、某次提名 | 地图上的具体地点 |
| 对象之间怎么连接? | Relationship / Property | hasFilm、hasNominee | 道路 |
| 什么数据算合法? | Constraint / Shape | winner 必须是 boolean | 交通规则 |
| 同一对象如何识别? | URI / Identifier | IMDb、TMDB、Wikidata ID | 身份证 / 门牌号 |
| 不同叫法如何对齐? | Controlled Vocabulary / Alignment | AwardConcept | 翻译词典 |
| 哪些事实可自动推出? | Inference | nominatedFor、inverse nominations | 按规则推出结论 |
再压缩一点:
Ontology =
名词表:有哪些类型
动词表:如何连接
规则书:什么合法
地址簿:如何识别同一对象
翻译表:不同叫法如何对齐
推理器:哪些事实可以推出
这比"ontology 是概念模型"更容易记。
因为它不只是概念。它是概念、关系、规则、标识和推理的组合。
本体论不是什么
为了避免误解,还需要说清楚 ontology 不是什么。
| 容易混淆的东西 | 它是什么 | 和 ontology 的区别 |
|---|---|---|
| 数据库 schema | 存储结构 | 更关心表、字段、索引和性能 |
| Taxonomy | 分类层级 | 通常只表达上下位关系,不表达复杂关系和约束 |
| Metadata catalog | 数据目录 | 记录有什么数据,但不一定定义如何解释和推理 |
| MDM / 主数据管理 | 整理可信主记录 | 更关心数据是否干净一致,ontology 更关心数据意味着什么 |
| Knowledge graph | 已填充的图 | ontology 是图的语义规则,graph 是实例化后的结果 |
| 数据清洗 | 修正脏数据 | ontology 能帮助发现问题,但不自动完成清洗 |
这几个东西可以配合使用,但层级不同。
数据库 schema 回答"数据怎么存"。Ontology 回答"数据意味着什么"。Knowledge graph 回答"这个世界里具体有哪些事实"。SHACL 这类约束语言回答"这些事实是否符合规则"。
如果把它们混在一起,就会出现很多误解。
比如有人说"我们已经有数据库表结构了,不需要 ontology"。但表结构只说明数据存在哪里,不一定说明业务上它意味着什么。category_id 可以连接两张表,但它不告诉你 Oscar Best Actor 和 SAG Male Actor 是否属于同一个成就概念。
也有人说"我们有知识图谱了,不需要 ontology"。但如果图谱里的边都是 relatedTo,类别没有对齐,标识符不稳定,那么这张图很难支持可靠推理。
为什么这对 AI 重要
AI 能访问数据,不等于理解数据。
它可以看到一堆字段、名字、文本和 ID,但如果没有稳定的语义结构,它只能猜:这个 category 是历史类别还是规范化类别?这个 Best Actor 和那个 Male Actor 是不是一回事?这个人名和另一个人名是不是同一个人?这个提名是否已经发生在可比较的奖项系统里?
Ontology 的价值是把这些问题提前结构化。
它让机器知道:
- 哪些对象存在。
- 哪些关系有意义。
- 哪些连接是合法的。
- 哪些标识代表同一个对象。
- 哪些不同叫法指向同一个概念。
- 哪些新事实可以按规则推出。
从这个角度看,MDM 和 ontology 的区别也更清楚。MDM 更像把人名、身份证号、客户号整理成可信主记录;ontology 则告诉系统这些对象和订单、产品、风险、权限、事件之间是什么关系。前者给 AI 可信记录,后者给 AI 使用这些记录的理解能力。
换一种更适合 AI 时代的说法:Ontology 可以被看作 AI 的持久化共享记忆层。Prompt 是临时说明,ontology 是长期记忆。Prompt 可以告诉模型这次任务怎么做,但 ontology 让多个模型、多个应用、多个 Agent 在同一个业务语言中工作。
所以当 AI 回答不好时,问题不一定先归因于模型能力。很多时候要先看对象类型是否清楚、关系是否有语义、实体是否对齐、约束是否完整。Ontology 质量会直接影响上下文质量,而上下文质量会影响 Agent 和模型的可靠性。
这就是为什么 FCKG 是一个适合讲本体论的例子。电影奖项足够熟悉,读者不需要先理解复杂业务;但它又足够复杂,有多个奖项系统、多个类别名称、人物与电影的多重关系、外部数据源和预测场景。
它让一个抽象问题变得可见:
如果你想让 AI 或模型稳定理解一个领域,不能只给它数据。你要先把这个领域组织成一个可计算的意义世界。
结尾
本体论不是知识图谱里的高级术语,也不是企业架构里的装饰概念。
它回答的是一个朴素但根本的问题:我们要让机器理解的这个世界,到底由什么组成?
FCKG 用电影奖项给了一个具体答案:这个世界里有 Film、Person、Nomination、AwardSystem、AwardCategory、AwardConcept、Identifier、Forecast。它们不是孤立名词,而是通过 hasFilm、hasNominee、realizationOf、predictsNomination 等关系连接起来,并受到 SHACL 约束和推理规则管理。
看懂这一点,再回头看 ontology,就不会只把它当术语表。
它更像一份可执行的领域说明书:规定这个世界有哪些对象、对象之间如何连接、什么数据算合法、同一对象如何被识别、不同叫法如何被对齐,以及哪些事实可以被自动推出。
真正决定 AI 能不能理解业务的,不是它能访问多少数据,而是这些数据是否已经被组织成一个可计算的意义世界。
参考资料
- FCKG GitHub Repository
- FCKG Interactive Ontology Diagram
- Using a Knowledge Graph to Generate Predictive Models for the Oscars
- W3C RDF Primer
- W3C OWL 2 Primer
- W3C SHACL Recommendation
- Thomas R. Gruber, "A Translation Approach to Portable Ontology Specifications", Knowledge Acquisition, 1993.