- Published on
构建 AI 智能体应用(二):工具选择策略与 MCP 生态演进
- Authors

- Name
- Shoukai Huang

Agent Types(Photo by Alvin Leopold on Unsplash)
系列导读: 本文是《Building Applications with AI Agents》系列解读的第二篇。在上一篇中,我们系统剖析了从反射型到深度研究型的六大核心架构模式;本篇将聚焦于智能体能力的延伸——工具使用 (Tool Use)。如何让智能体在数以万计的工具中精准定位并高效执行?我们将从基础模式出发,一路推演至 2026 年最前沿的 MCP 生态与图增强架构。
1. 引言:从有限调用到无限生态
步入 2026 年,企业级 Agent 系统面临着前所未有的扩展性挑战:如何从数百、数千甚至数万个工具中,准确且高效地选择出最合适的那一个?这不仅关乎响应延迟(Latency)与计算成本(Cost),更直接决定了 Agent 解决复杂现实问题的能力上限。
如果说智能体类型定义了 Agent 的“大脑”思考方式,那么工具选择则决定了 Agent 的“手脚”执行边界。本文将系统梳理 Agent 工具选择(Tool Selection)的演进路径——从早期基于上下文的标准选择,到目前作为业界标配的 Tool RAG,再到面向未来的模型上下文协议(MCP)生态。

2. 经典工具选择策略 (The Classics)
在 Agent 发展的早期,工具数量有限(通常 < 10 个),我们主要依赖几种直观且易于实现的策略。
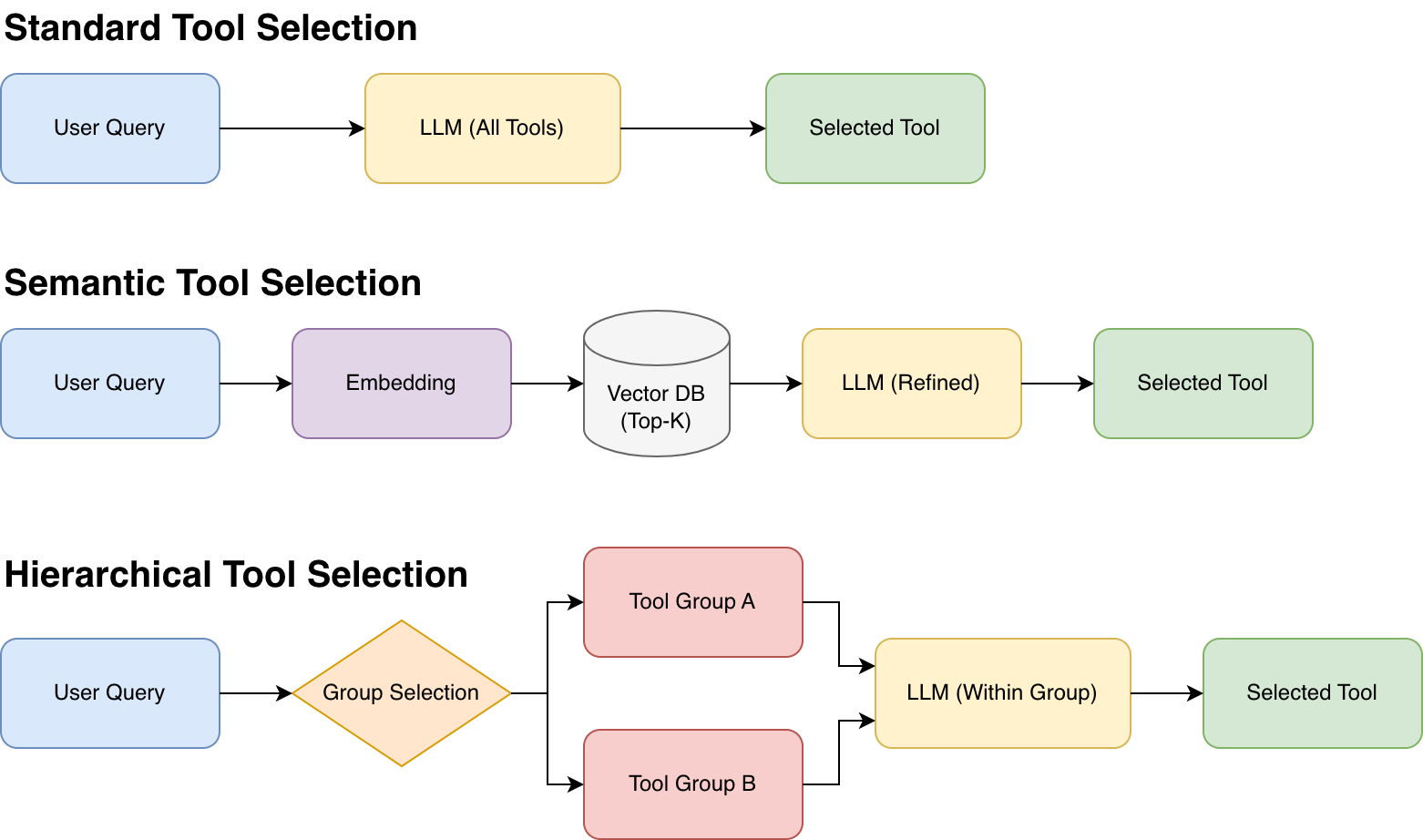
2.1 标准工具选择 (Standard Tool Selection)
直接的上下文注入
形象比喻: 开卷考试的选择题 —— 试卷上列出了所有选项(工具),考生(LLM)根据题目(用户指令)直接勾选。
这是最基础的方法。我们将所有的工具定义(Definition)与描述(Description)直接放入 System Prompt 中,让大语言模型根据当前的上下文选择最合适的工具。
- 典型工作流:
- User: "查询北京天气"
- System: "可用工具: [get_weather, get_stock, send_email...]"
- Agent: "选择 get_weather(location='Beijing')"
- 优势: 实现简单,利用 In-context Learning 可快速提升准确率。
- 劣势:
- 上下文限制: 无法应对工具数量激增的场景。
- 高延迟: 每次请求都需处理大量无关的工具描述。
2.2 语义工具选择 (Semantic Tool Selection)
基于向量的按需检索
形象比喻: 图书馆检索终端 —— 输入关键词,系统返回最相关的几本书,而不是把整个图书馆的书名都列出来。
为了解决 Token 限制,引入了语义检索(Semantic Retrieval)。预先将工具描述转换为向量(Vector)存入数据库,使用时动态召回。
- 典型工作流:
- Embedding: 将所有工具描述向量化。
- Retrieve: 根据 User Query 检索 Top-K (如 Top-5) 工具。
- Select: 仅将这 5 个工具注入 Prompt 供 Agent 选择。
- 优势: 支持数百个工具的规模,大幅降低 Token 消耗。
- 劣势: 依赖 Embedding 质量,容易出现语义碰撞(Semantic Collision)。
2.3 分层式工具选择 (Hierarchical Tool Selection)
分类导航与逐级定位
形象比喻: 超市导购 —— 先找“食品区”,再找“饮料架”,最后拿“可乐”。
当工具功能重叠严重时,采用分层策略:先选择“工具组/类别”,再选择具体工具。
- 典型工作流:
- Router: "用户问的是财务问题,选择 'Finance Toolkit'"。
- Selector: 加载 Finance Toolkit 中的 20 个工具,选择
query_balance。
- 优势: 将大问题拆解为小问题,提高准确率。
- 劣势: 增加了交互轮次,导致系统延迟增加。
3. 2026 主流架构:Tool RAG 及其深度优化
随着企业级 Agent 的落地,Tool RAG (Retrieval-Augmented Generation for Tools) 已成为 2026 年的业界标准。其核心是将“工具选择”转化为一个“检索 + 生成”的 RAG 问题。为解决语义模糊问题,现代架构引入了多项关键优化:
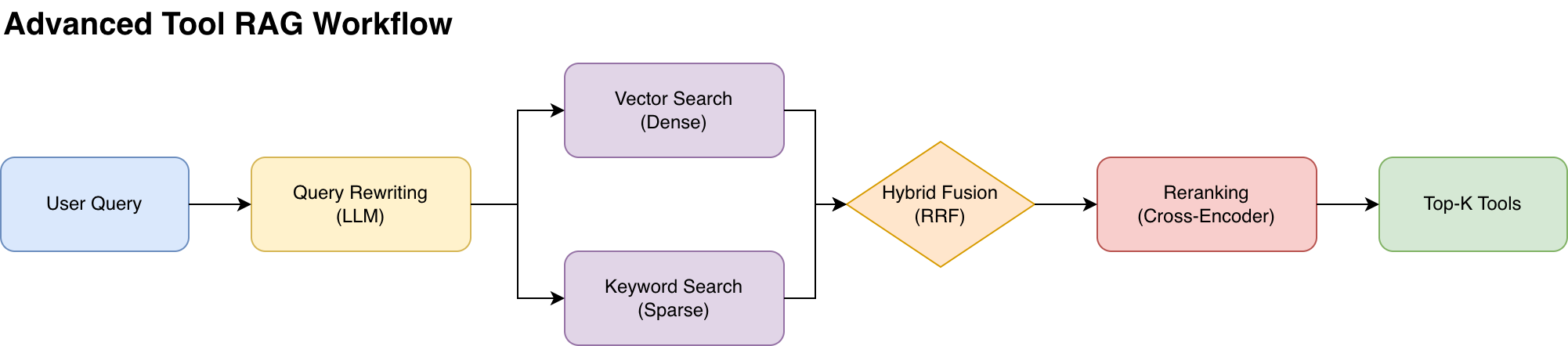
3.1 查询改写 (Query Rewriting)
用户的提问往往是模糊或口语化的(例如:“帮我查一下上周数据”)。直接检索工具描述效果不佳。
- HyDE (Hypothetical Document Embeddings): 先让 LLM 生成一个假设性的“理想工具描述”,再用该描述去检索。
- Multi-query: 生成 3-5 个不同角度的查询变体,扩大召回范围。
3.2 示例查询嵌入 (Example Queries Embedding)
这是提升检索质量的杀手锏。
- 传统做法: Embedding 工具的“功能描述”(通常抽象且技术化)。
- 2026 实践: 为每个工具生成 10-20 个“典型用户 Query”,并对这些 Query 进行 Embedding。
- 效果: 检索时是用“用户 Query”匹配“示例 Query”,语义相似度与召回率大幅提升。
3.3 混合检索与重排序 (Hybrid Search & Reranking)
- 混合检索: 同时使用向量检索(捕捉语义)和关键词检索(BM25,捕捉专有名词),通过 RRF 算法融合。
- 重排序: 先召回 Top-50,再使用轻量级 Cross-Encoder 模型进行精细排序,最终只给 Agent 提供 Top-5,兼顾了速度与精度。
4. 应对复杂依赖:图增强检索 (Graph-enhanced Tool RAG)
在企业内部 API 场景中,工具之间往往存在强依赖(如:先 login 获取 Token,才能 get_data)。纯粹的语义检索容易丢失这种关联。
形象比喻: 地铁线路图 —— 你不能只知道“终点站”,必须知道“换乘路线”。
解决方案: 构建工具图谱(Tool Graph)。
- 节点 (Nodes): 代表工具。
- 边 (Edges): 代表依赖关系 (DependsOn)、共现关系 (Co-occurrence) 或 领域关系 (IsRelatedTo)。
典型工作流:
- Retrieve: 检索到核心工具
get_data。 - Traverse: 在图谱中遍历其前置依赖(
login)和后置操作(format_report)。 - Inject: 将整个子图涉及的工具一并提供给 Agent。
5. 开放生态:MCP 与动态发现
如果我们将视野放宽到跨组织、跨平台的万级工具生态,单一 Agent 预加载所有工具描述已不再可行。
模型上下文协议 (Model Context Protocol, MCP) 的出现彻底改变了游戏规则。它就像 AI 时代的 USB-C 接口,标准化了 Agent 与工具(Server)的连接方式。
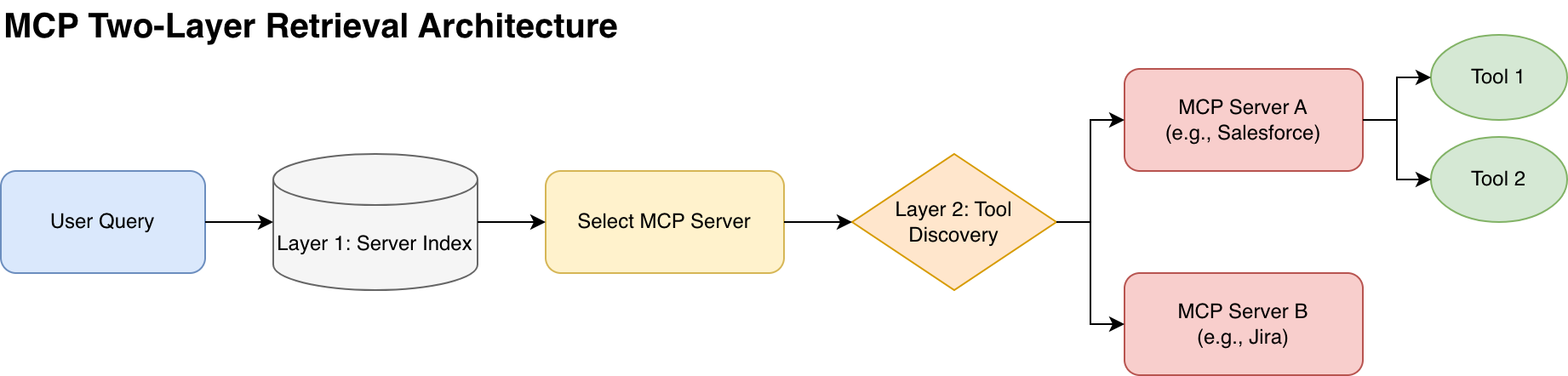
5.1 Tool-to-Agent 双层检索架构
在 MCP 生态下,工具选择从“静态预置”转向了“动态发现”:
- Layer 1 - Server Discovery:
- 根据用户意图,首先检索出最相关的 MCP Server。
- 例:“我要分析 Salesforce 数据” -> 定位到
Salesforce MCP Server。
- Layer 2 - Tool Discovery:
- Agent 连接到该 Server,通过
list_tools协议动态获取当前可用的工具列表。 - 这种类似 DNS 的动态发现机制,实现了真正的无限扩展能力。
- Agent 连接到该 Server,通过
6. 内容层演进:Agent Skills 标准
除了“找工具”,Agent 还需要知道“怎么用”。Agent Skills(以 Anthropic Skills 为代表)专注于内容层面 (Content Level) 的标准化。
形象比喻: 菜谱 (Recipes) —— MCP 提供了厨房工具(刀、锅),Skills 则是教你如何做红烧肉的菜谱。
6.1 渐进式揭露 (Progressive Disclosure)
Skills 遵循“渐进式揭露”原则,避免一次性加载所有细节:
- 元数据层 (Metadata): 仅包含名称和适用场景,常驻内存。
- 指导层 (Instruction): 选中 Skill 后加载详细步骤和最佳实践。
- 执行层 (Implementation): 仅在执行时加载具体的 Python 脚本或 API 模板。
这种设计使得 Agent 能够学习复杂的业务流程(如“故障排查标准作业程序”),而不仅仅是单点的工具调用。
7. 工具选择策略综合对比
下表总结了 2026 年主流的工具选择策略,为您提供选型参考。
| 策略方向 | 形象比喻 | 核心优势 | 核心劣势 | Scaling 能力 | 2026 主流度 |
|---|---|---|---|---|---|
| Standard (标准选择) | 开卷考试 | 简单直观 无需额外设施 | 上下文溢出 高延迟 | 低 (< 50) | ★★ (仅用于 Demo) |
| Tool RAG (检索增强) | 搜索引擎 | 平衡了成本与规模 支持海量工具 | 需维护向量库 语义模糊风险 | 高 (数千) | ★★★★★ (企业标配) |
| Graph RAG (图增强) | 地铁导航 | 解决依赖问题 保障流程完整性 | 构建图谱成本高 复杂度高 | 中高 (特定领域) | ★★★★ (复杂业务必选) |
| MCP (开放协议) | USB 接口 | 跨平台互通 动态热插拔 | 依赖生态支持 网络延迟 | 极高 (无限) | ★★★★★ (生态基础) |
| Agent Skills (技能标准) | 菜谱指南 | 固化最佳实践 提升行为一致性 | 编写成本高 需专家知识 | 极高 (内容层) | ★★★★ (高阶智能体) |
8. 结语
工具选择机制的进化,本质上是 Agent 认知边界的扩张。从早期的死记硬背(Standard),到学会查阅字典(Tool RAG),再到掌握使用外部设备的通用协议(MCP),Agent 正逐步具备适应开放世界的能力。
在下一篇文章中,我们将探讨多智能体协作中的编排模式 (Orchestration Patterns),看看这些具备了强大工具使用能力的 Agent 们,是如何像人类团队一样分工协作的。